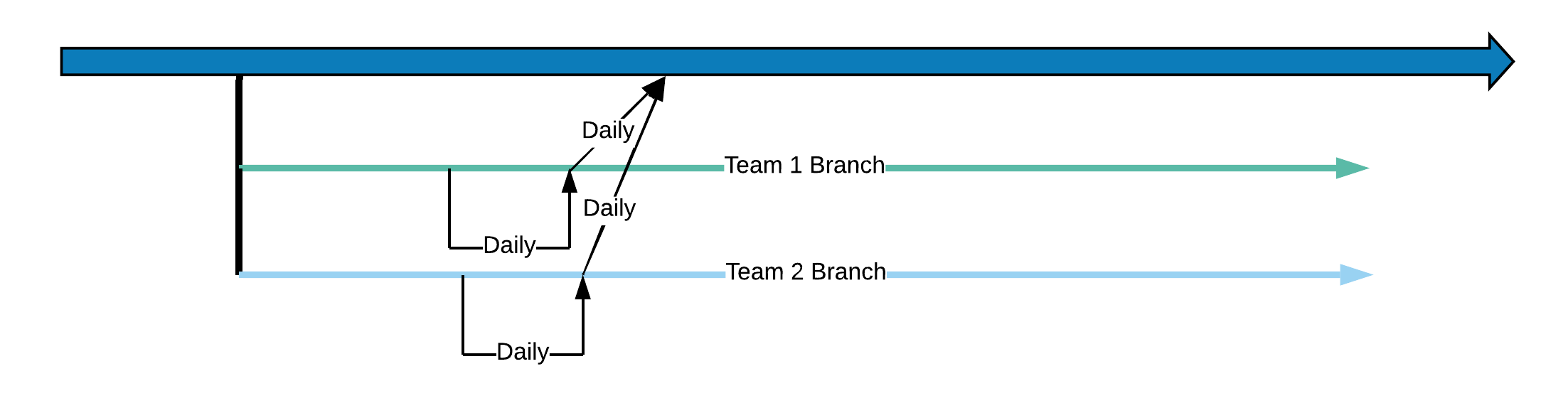These are the core skills we recommend everyone learn to execute CD.
Behavior-Driven Development
Every step in CD requires clear, testable acceptance criteria as a prerequisite. BDD is not test automation. BDD is the
discussion that informs acceptance test driven development.
“Any organization that designs a system will produce a design whose structure is a copy of the
organization’s communication structure.” - Melvin Conway
Loosely coupled teams create loosely coupled systems. The opposite is also true.
The ability to deliver the latest changes to production on demand.
Continuous Deployment
Delivering the latest changes to production as they occur.
Continuous Integration
Continuous integration requires that every time somebody commits any change, the entire application is built and a comprehensive
set of automated tests is run against it. Crucially, if the build or test process fails, the development team stops whatever they
are doing and fixes the problem immediately. The goal of continuous integration is that the software is in a working state all the
time.
Continuous integration is a practice, not a tool. It requires a degree of commitment and discipline from your development team.
You need everyone to check in small incremental changes frequently to mainline and agree that the highest priority task on the
project is to fix any change that breaks the application. If people don’t adopt the discipline necessary for it to work, your
attempts at continuous integration will not lead to the improvement in quality that you hope for.
– “Continuous Delivery: Reliable Software Releases through Build, Test, and Deployment
Automation.” - Jez Humble & David Farley
A hard dependency is something that must be in place before a feature is
delivered. In most cases, a hard dependency can be converted to a soft dependency with feature flags.
Soft Dependency
A soft dependency is something that must be in place before a feature can be fully functional, but does not block the
delivery of code.
Story Points
A measure of the relative complexity of delivering a story. Historically, 1 story point was 1 “ideal
day”. An ideal day is a day where there are no distractions, the code is flowing, and we aren’t waiting on anything. No
such day exists. :wink:
There are many common story point dysfunctions: pointing defects, unplanned work, and spikes are some of the more
common. Adjusting points after work is done is another common mistake. The need for story points is a good indication
that we do not understand the work. If we have decomposed the work correctly, everything should be 1 point.
Toil
The repetitive, predictable, constant stream of tasks related to
maintaining an application.
Any work that the team inserts before the current planned work. Critical defects and “walk up” requests are unplanned
work. It’s important that the team track all unplanned work and the reason so that steps can be taken by the team to
reduce the future impact.
Vertical Sliced Story
A story should represent a response to a request that can be deployed
independently of other stories. It should be aligned across the tech stack so
that no other story needs to be deployed in concert to make the function work.
Examples:
Submitting a search term and returning results.
Requesting user information from a service and receiving a response.
WIP
Work in progress is any work that has been started but not delivered to the end-user
Continuous delivery is the ability to deliver the latest changes on-demand. CD is not build/deploy automation. It is the continuous flow of changes to the end-user with no human touchpoints between code integrating to the trunk and delivery to production. This can take the form of triggered delivery of small batches or the immediate release of the most recent code change.
CD is not a reckless throwing of random change into production. Instead, it is a disciplined team activity of relentlessly automating all of the validations required for a release candidate, improving the speed and reliability of quality feedback, and collaborating to improve the quality of the information used to develop changes.
CD is based on and extends the extreme programming practice of continuous integration. There is no CD without CI.
The path to continuous integration and continuous delivery may seem daunting to teams that are just starting out. We offer this guide to getting started with a focus on outcome metrics to track progress.
Continuous Delivery is far more than automation. It is the entire cycle of identifying value, delivering the value, and verifying
with the end user that we delivered the expected value. The shorter we can make that feedback loop, the better our bottom line will
be.
Goals
Both CI and CD are behaviors intended to improve certain goals. CI is very effective at uncovering issues in work decomposition and testing within the team’s processes so that the team can improve them. CD is effective at uncovering external dependencies, organizational process issues, and test architecture issues that add waste and cost.
The relentless improvement of how we implement CD reduces overhead, improves quality feedback, and improves both the outcomes of the end-user and the work/life balance of the team.
CD Maturity
It has been common for organizations to apply “maturity models” to activities such as CD. However, this has been found to lead to cargo culting and aligning goals to the process instead of the outcomes. Understanding what capabilities you have and what capabilities need to be added to fully validate and operate changes are important, but the goals should always align to improving the flow of value delivery to the end-user. This requires analyzing every process from idea to delivery and identifying what should be removed, what should be automated, and how we can continuously reduce the size of changes delivered.
There should never be an understanding that we are “mature” or “immature” with delivery. We can always improve. However, there should be an understanding of what competency looks like.
Minimums
Each developer integrates tested changes to the trunk at least daily.
Changes always use the same process to deliver.
There are no process differences between deploying a feature or a fix.
There are no manual quality gates.
All test and production environments use the same artifact.
If the release cadence requires release branches, then the release branches deploy to all test environments and production.
Good
New work requires less than 2 days from start to delivery
All changes deliver from the trunk
The time from committing change and delivery to production is less than 60 minutes
Less than 5% of changes require remediation
The time to restore service is less than 60 minutes.
Continuous Integration
This working agreement for CI focuses on developing teamwork and delivering quality outcomes while removing waste.
Branches originate from the trunk.
Branches are deleted in less than 24 hours.
Changes must be tested and not break existing tests before merging to the trunk.
Changes are not required to be “feature complete”.
Helping the team complete work in progress (code review, pairing) is more important than starting
new work.
Fixing a broken build is the team’s highest priority.
Desired outcomes:
More frequent integration of smaller, higher quality, lower risk changes.
Small, cohesive, high morale, high-performing product teams with business domain expertise.
Recommended Practices
While implementation is contextual to the product, there are key
steps that should be done whenever starting the CD journey.
Value Stream Map: This is a standard Lean tool to make visible
the development process and highlight any constraints the team has. This is a
critical step to begin improvement.
Build a road map of the constraints and use a disciplined improvement process
to remove the constraints.
Align to the Continuous Integration team working agreement and use the
impediments to feed the team’s improvement process.
We always branch from Trunk.
Branches last less than 24 hours.
Changes must be tested and not break existing tests.
Changes are not required to be “feature complete”.
Code review is more important than starting new work.
Fixing a broken build is the team’s highest priority.
Build and continuously improve a single CD automated pipeline for each
repository. There should only be a single configuration for each repository
that will deploy to all test and production environments.
A valid CD process will have only a single method to build and deploy any
change. Any deviation for emergencies indicates an incomplete CD process that
puts the team and business at risk and must be improved.
Pipeline
Focus on hardening the pipeline. Its job is to block bad changes. The team’s job is to develop its ability to do that. Only use the emergency process. If a process will not be used to resolve a critical outage, it should not be happening in the CD pipeline.
Integrate outside the pipeline. Virtualize inside the pipeline. Direct integration is not a good testing method for validating behavior because the data returned is not controlled. It IS a good way to validate service mocks. However, if done in the pipeline it puts fixing production at risk if the dependency is unavailable.
There should be one or fewer stage gates. Until release and deploy are decoupled, one approval for production. No other stage gates.
Developers are responsible for the full pipeline. No handoffs. Handoffs cause delays and dilute ownership. The team owns its pipelines and the applications they deploy from birth to death.
Short CI Cycle Time
CI cycle time should be less than 10 minutes from commit to artifact creation. CD cycle time should be less than 60 minutes from commit to Production.
Integrate outside the pipeline. Virtualize inside the pipeline
Direct integration to stateful dependencies (end-to-end testing) should be avoided in the pipeline. Tests in the pipeline should be deterministic and the larger the number of integration points the more difficult it is to manage state and maintain determinism. It is a good way to validate service mocks. However, if done in the pipeline it puts fixing production at risk if the dependency is unstable/unavailable.
All test automation pre-commit
Tests should be co-located with the system under test and all acceptance testing should be done by the development team. The goal is not 100% coverage. The goal is efficient, fast, effective testing.
No manual steps
There should be no manual intervention after the code is integrated into the trunk. Manual steps inject defects.
The following are very frequent issues that teams encounter when working to improve the flow of delivery.
Work Breakdown
Stories without testable acceptance criteria
All stories should be defined with declarative and testable acceptance criteria. This reduces the amount
of waiting and rework once coding begins and enables a much smoother testing workflow.
Acceptance criteria should define “done” for the story. No behavior other than that specified by the acceptance
criteria should be implemented. This ensures we are consistently delivering what was agreed to.
Stories too large
It’s common for teams using two week sprints to have stories that require five to ten days to complete. Large stories hide complexity, uncertainty, and dependencies.
Stories represent the smallest user observable behavior change.
To enable rapid feedback, higher quality acceptance
criteria, and more predictable delivery, Stories should require no more than two days for a team to deliver.
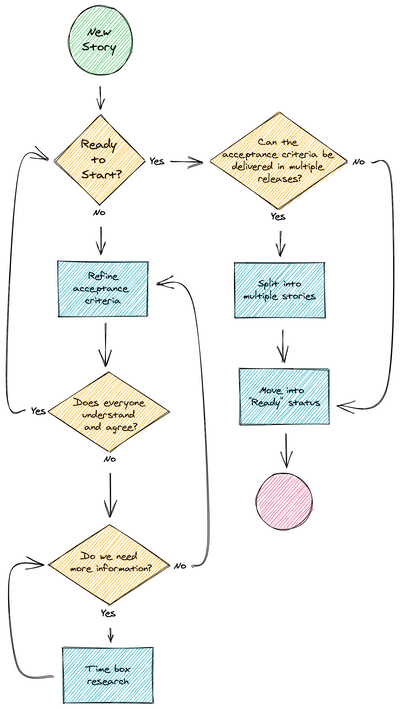
No definition of “ready”
Teams should have a working agreement about the definition of “ready” for a story or task. Until the team agrees it has
the information it needs, no commitments should be made and the story should not be added to the “ready” backlog.
Definition of Ready
- Story
- Acceptance criteria aligned with the value statement agreed to and understood.
- Dependencies noted and resolution process for each in place
- Spikes resolved.
- Sub-task
- Contract changes documented
- Component acceptance tests defined
No definition of “Done”
Having an explicit definition of done is important to keeping WIP low and finishing work.
Definition of Done
- Sub-task
- Acceptance criteria met
- Automated tests verified
- Code reviewed
- Merged to Trunk
- Demoed to team
- Deployed to production
- Story
- PO Demo completed
- Acceptance criteria met
- All tasks "Done" - Deployed to production
Team Workflow
Assigning tasks for the sprint
Work should always be pulled by the next available team member. Assigning tasks results in each team member working in isolation on a task list instead of the team
focusing on delivering the next high value item. It also means that people are less invested in the work other people
are doing. New work should be started only after helping others
complete work in progress.
Co-dependant releases
Multi-component release trains increase batch size and reduce delivered quality. Teams cannot improve efficiency if they
are constantly waiting. Handle dependencies with code, do not manage them with process. If you need a person to
coordinate releases, things are seriously broken.
Handoffs to other teams
If the normal flow of work requires waiting on another team then batch sizes increase and quality is reduced. Teams
should be organized so they can deliver their work without coordinating outside the team.
Early story refining
As soon as we decide a story has been refined to where we can begin developing it, the information begins to age because
we will never fully capture everything we decided on. The longer a story is “ready” before we being working, the less
context we retain from the conversation. Warehoused stories age like milk. Limit the inventory and spend more time on
delivering current work.
Manual test as a stage gate
In this context, a test is a repeatable, deterministic activity to verify the releasability of the system. There are
manual activities related to exploration of edge cases and how usable the application is for the intended consumer, but these
are not tests.
There should be no manual validation as a step before we deploy a change. This includes, but is not limited to manual
acceptance testing, change advisory boards (CAB), and manual security testing.
Meaningless retrospectives
Retrospectives should be metrics driven. Improvement items should be treated as business features.
Hardening / Testing / Tech Debt Sprints
Just no. These are not real things. Sprints represent work that can be
delivered to production.
Moving “resources” on and off teams to meet “demand”
Teams take time to grow, they cannot be “constructed”. Adding or removing anyone
from a team lowers the team’s maturity and average problem space expertise. Changing too many people on a team
reboots the team.
One delivery per sprint
Sprints are planning increments, not delivery increments. Plan what will be delivered daily during the sprint.
Skipping demo
If the team has nothing to demo, demo that. Never skip demo.
Committing to distant dates
Uncertainty increases with time. Distant deliverables need detailed analysis.
Not committing to dates
Commitments drive delivery. Commit to the next Minimum Viable Feature.
Velocity as a measure of productivity
Velocity is planning metric. “We can typically get this much done in this much time.” It’s an estimate of relative
capacity for new work that tends to change over time and these changes don’t necessarily indicate a shift in productivity. It’s
also an arbitrary measure that varies wildly between organizations, teams and products. There’s no credible means of
translating it into a normalized figure that can be used for meaningful comparison.
By equating velocity with productivity there is created an incentive to optimize velocity at the expense of developing quality software.
CD Anti-Patterns
Work Breakdown
Issue
Description
Good Practice
Unclear requirements
Stories without testable acceptance criteria
Work should be defined with acceptance tests to improve clarity and enable developer driven testing.
Long development Time
Stories take too long to deliver to the end user
Use BDD to decompose work to testable acceptance criteria to find smaller deliverables that can be completed in less than 2 days.
Workflow Management
Issue
Description
Good Practice
Rubber band scope
Scope that keeps expanding over time
Use BDD to clearly define the scope of a story and never expand it after it begins.
Focusing on individual productivity
Attempting to manage a team by reporting the “productivity” of individual team members. This is the fastest way to destroy teamwork.
Measure team efficiency, effectiveness, and morale
Estimation based on resource assignment
Pre-allocating backlog items to the people based on skill and hoping that those people do not have life events.
The whole team should own the team’s work. Work should be pulled in priority sequence and the team should work daily to remove knowledge silos.
Meaningless retrospectives
Having a retrospective where the outcome does not results in team improvement items.
Focus the retrospective on the main constraints to daily delivery of value.
Skipping demo
No work that can be demoed was completed.
Demo the fact that no work is ready to demo
No definition of “Done” or “Ready”
Obvious
Make sure there are clear entry gates for “ready” and “done” and that the gates are applied without exception
One or fewer deliveries per sprint
The sprint results in one or fewer changes that are production ready
Sprints are planning increments, not delivery increments. Plan what will be delivered daily during the sprint. Uncertainty increases with time. Distant deliverables need detailed analysis.
Pre-assigned work
Assigning the list of tasks each person will do as part of sprint planning. This results in each team member working in isolation on a task list instead of the team focusing on delivering the next high value item.
The whole team should own the team’s work. Work should be pulled in priority sequence and the team should work daily to remove knowledge silos.
Teams
Issue
Description
Good Practice
Unstable Team Tenure
People are frequently moved between teams
Teams take time to grow. Adding or removing anyone from a team lowers the team’s maturity and average expertise in the solution. Be mindful of change management
Poor teamwork
Poor communication between team members due to time delays or “expert knowledge” silos
Make sure there is sufficient time overlap and that specific portions of the system are not assigned to individuals
Multi-team deploys
Requiring more than one team to deliver synchronously reduces the ability to respond to production issues in a timely manner and delays delivery of any feature to the speed of he slowest teams.
Make sure all dependencies between teams are handled in ways that allow teams to deploy independently in any sequence.
Testing Process
Issue
Description
Good Practice
Outsourced testing
Some or all of acceptance testing performed by a different team or an assigned subset of the product team.
Building in the quality feedback and continuously improving the same is the responsibility of the development team.
Manual testing
Using manual testing for functional acceptance testing.
Manual tests should only be used for things that cannot be automated. In addition, manual tests should not be blockers to delivery but should be asynchronous validations.
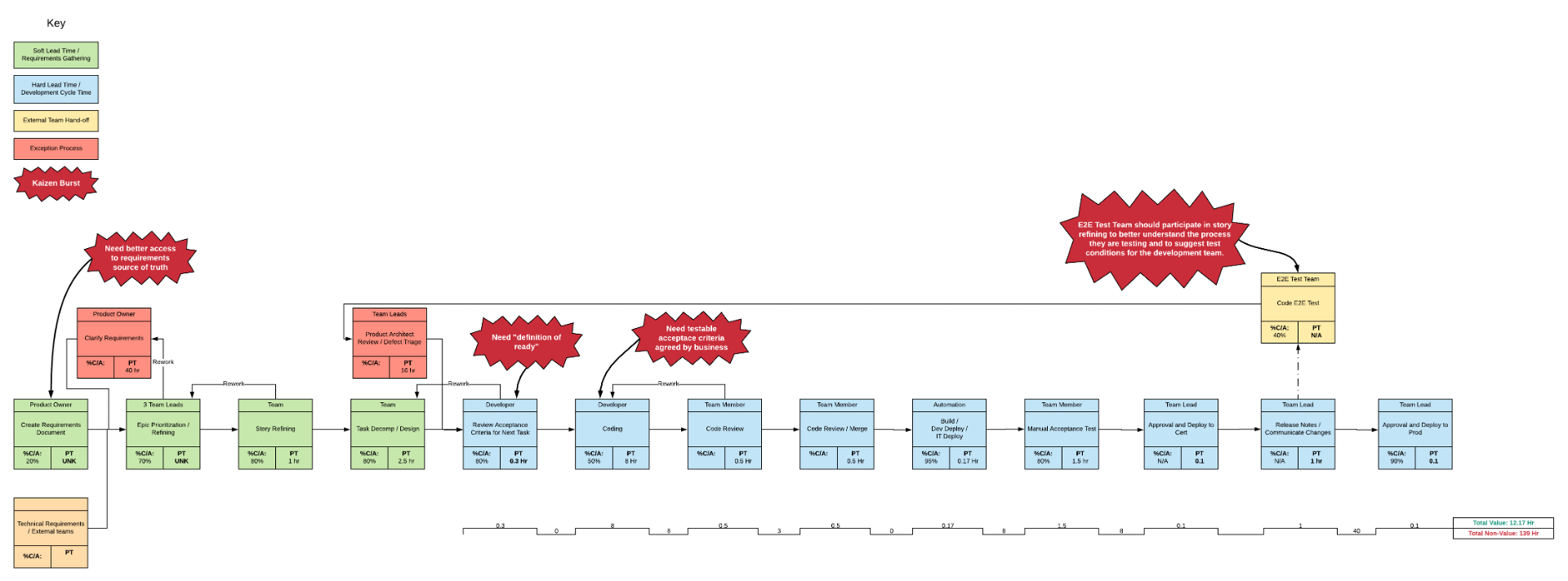
2.2 - Pipeline & Application Architecture
Whenever teams or areas want to improve their ability to deliver, there is a recommended order of operations to ensure the
improvement is effective. This value stream improvement journey’s goal is to provide the steps and guide you to good implementation
practices.
Before any meaningful improvement can happen, the first constraint must be cleared. We need to make sure there is a single,
automated deployment pipeline to production. Human intervention after the code is integrated should be limited to approving
stage gates to trigger automation where needed.
A well-architected pipeline will build an artifact once and deploy that artifact to all required test environments for validation
and deliver changes safely to production.
It will also trigger all of the tests and provide rapid feedback as near the source of failure as possible. This is critical for
informing the developer who created the defect so that they have the chance to learn the reasons the defect was created and prevent
future occurrences.
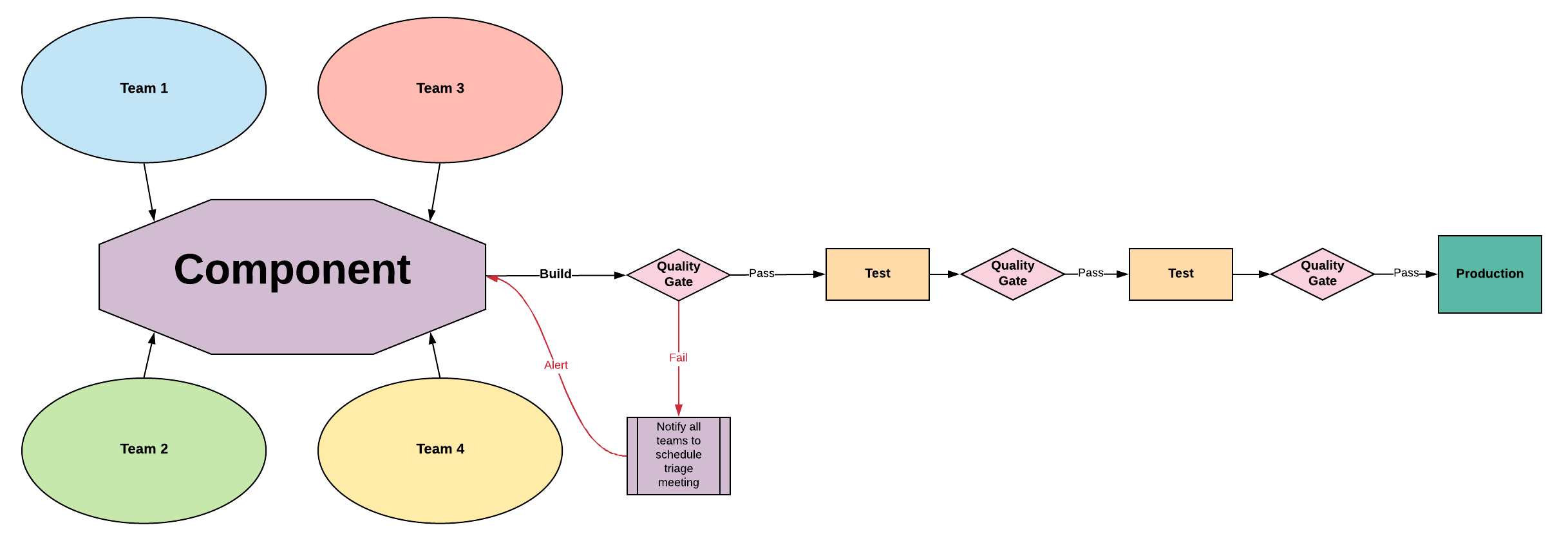
Entangled Architecture - Requires Remediation
With an entangled architecture, there is no clear ownership of individual components or their quality. Every team could cause a
defect anywhere in the system because they are not working within product boundaries. The pipeline’s quality signal will
be delayed compared to better-optimized team architectures. When a defect is found, it will require effort to identify
which team
created the defect and a multi-team effort to improve the development process to prevent regression. Continuous delivery
is difficult with this architecture.
The journey to CD begins with each team executing continuous
integration on a team branch and those branches are
integrated automatically into a master CI flow daily.
Any breaks in the pipeline should be addressed immediately by the team who owns the branch.
Common Entangled Practices
Team Structure: Feature teams focused on cross-cutting deliverables instead of product ownership and capability expertise.
**Development Process: Long-lived feature branches integrated after features are complete
Branching: Team branches with each team working towards CI on their branch and daily integration of team branches
to the trunk that re-runs the team-level tests.
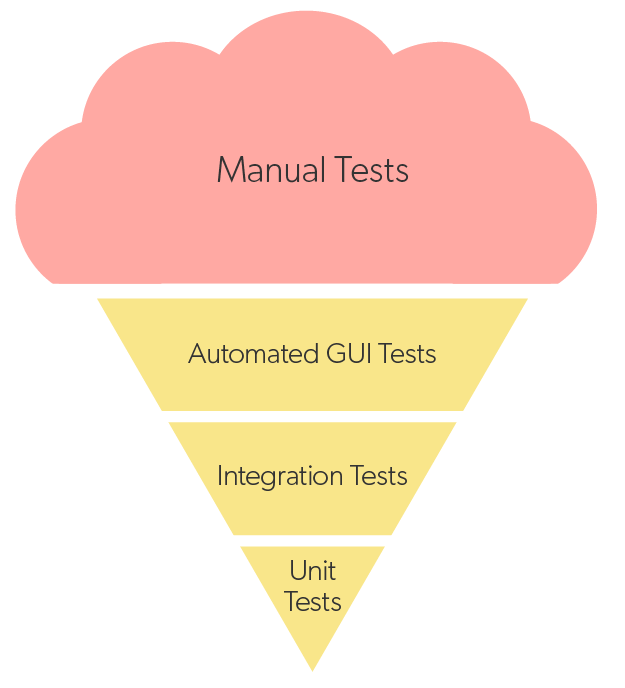
Inverted Test Pyramid: The “ice cream cone testing” anti-pattern is
common. However, the teams should be focusing on improving the quality feedback and engineering tests that alert earlier
in the build cycle.
Pipeline: Establishing reliable build/deploy automation is a high priority.
Deploy Cadence / Risk: Delivery cadence in this architecture tends to be extended. This in turn leads to large code
change delta and high risk.
Improvement Plan
Find the architectural boundaries in the application that can be used to divide sub-systems between the
teams to create product teams. This step will realign the teams to a tightly coupled
architecture with defined ownership, will improve quality outcomes, and
allow them to further decouple the system using the Strangler](https://martinfowler.com/bliki/StranglerFigApplication.html) process
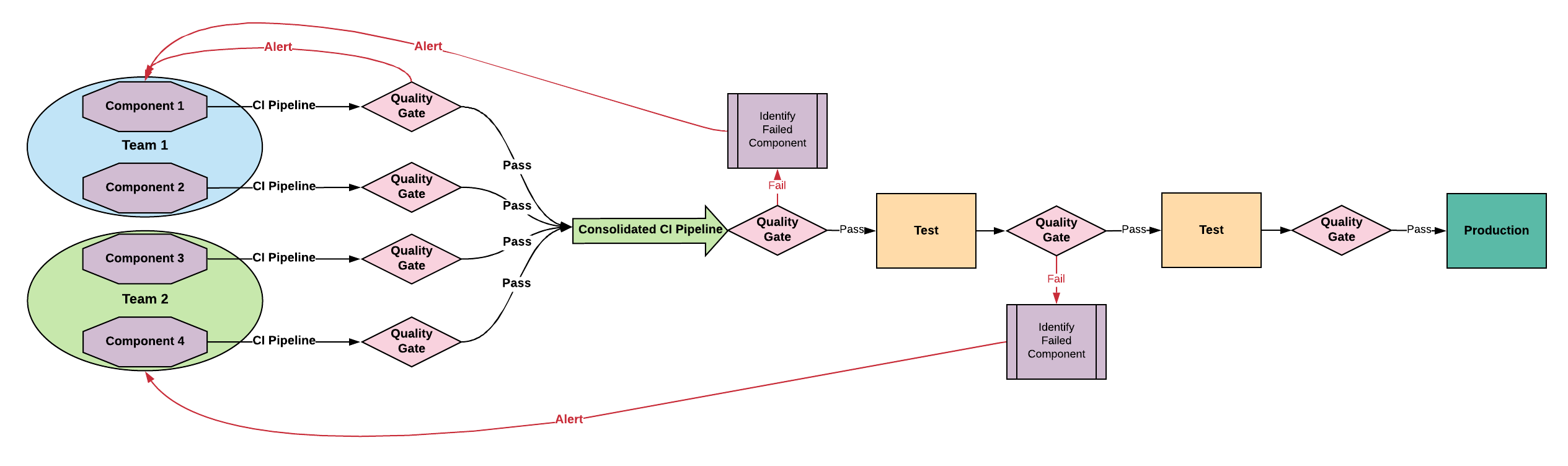
Tightly Coupled Architecture - Transitional
With tightly coupled architecture, changes in one portion of the application can cause unexpected changes in another portion of
the application. It’s quite common for even simple changes to take days or weeks of analysis to verify the implications of the
change.
Tightly coupled applications have sub-assemblies assigned to product teams along logical application boundaries. This enables each
team to establish a quality signal for their components and have the feedback required for improving their quality process. This
architecture requires a more complicated integration pipeline to make sure each of the components can be tested
individually and as a larger application. Simplifying the pipelines and decoupling the application will result in higher
quality with less overhead.
Common Tightly Coupled Practices
Team Structure: Product teams focused on further de-coupling sub-systems
Development Process: Continuous integration. Small, tested changes are applied to the trunk as soon as complete on each product team. In addition, a larger CI pipeline is required to frequently run larger tests on the
integrated system, at least once per day.
Developer Driven Testing: The team is responsible for
architecting and continuously improving a suite of tests that give rapid feedback on quality issues. The team is also responsible
for the outcomes of poor testing, such as L1 support. This is a critical feedback loop for quality improvement.
Pipeline: CI pipeline working to progress to continuous delivery.
Deploy Cadence / Risk: Deliveries can be more frequent. Risk is inversely proportional to delivery frequency.
For infrequently changed portions of the application that are poorly tested, re-writing may result in lost business
capabilities. Wrapping these components in an API without re-architecting may be a better solution.
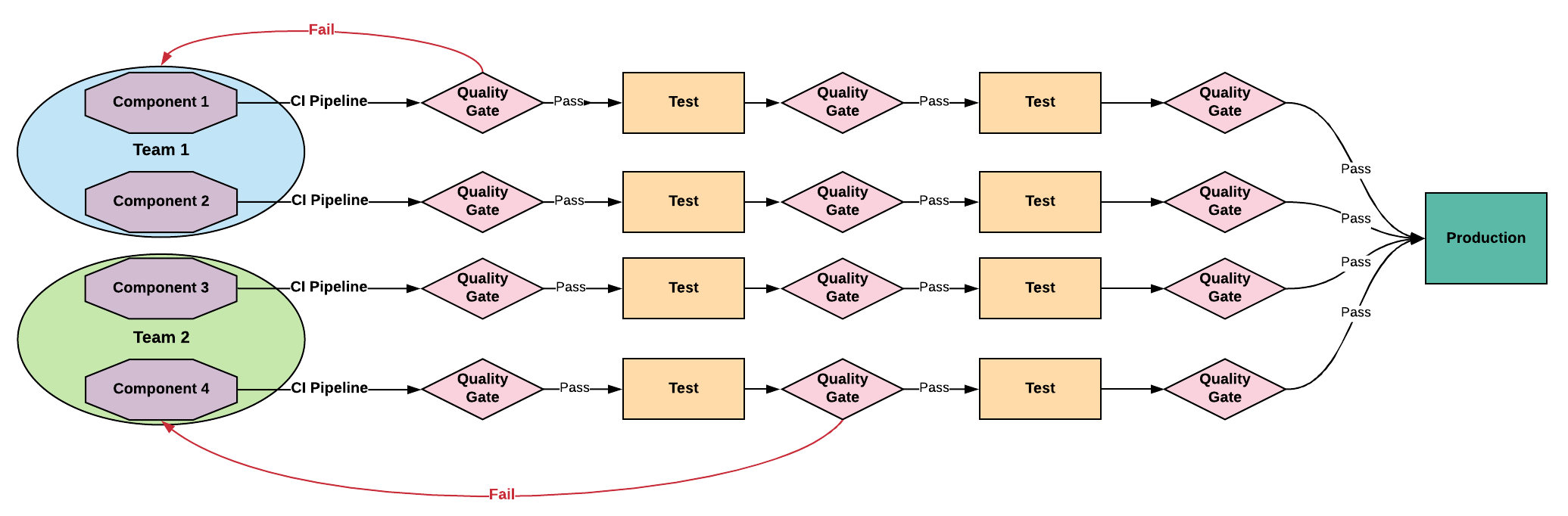
Loosely Coupled Architecture - Goal
With a loosely coupled architecture, components are delivered independently of each other in any sequence. This reduces
complexity and improves quality feedback loops. This not only relies on clean separations of teams and sub-assemblies but also on mature testing practices that include the use of virtual services to verify integration.
Developer Driven Testing: The team is responsible for
architecting and continuously improving a suite of tests that give rapid feedback on quality issues. The team is also responsible
for the outcomes of poor testing, such as L1 support. This is a critical feedback loop for quality improvement.
Pipeline: One or more CD pipelines that are independently deployable at any time in any sequence.
Deploy Cadence / Risk: Deliveries can occur on demand or immediately after being verified by the pipeline. Risk is
inversely proportional to delivery frequency.
2. Stabilize the Quality Signal
Establishing a production pipeline allows us to evaluate and improve our quality signal. Quality gates should
be designed to inform the team of poor quality as close to the source as possible. This goal will be disrupted by
unstable tests.
Remediating Test Instability
Unstable test results will create a lack of trust in the test results and encourage bypassing test failure. To correct this:
Remove flaky tests from the pipeline
to ensure that tests in the pipeline are trusted by the team
Identify the causes for test instability and take corrective action
If the test can be stabilized and provides value, correct it and move it back into the pipeline
If it cannot be stabilized but is required, schedule it to run outside the pipeline
If not required, remove it
In general, bias should be towards testing enough, but not over-testing. Tracking the
duration of the pipeline and enacting a quality gate for maximum pipeline duration (from PR merge to production) is a good way to keep testing efficient.
After stabilizing the quality signal, we can track where most of the defects are detected and the type of defects they
are. Start tracking the trends for the number of defects found in each environment and the root cause distribution of
the defects to inform the test suite improvement plan. Then focus the improvements on moving the majority of defect detection closer to the developer. The ultimate goal is for most defects to be trapped in the developer’s environment and not leak into the
deployment pipeline.
3. Continuous Improvement
After removing noise from the quality signal, we need to find and remove more waste on a
continuous basis. We start by mapping the deployment process from coding to production delivery and identifying the choke points
that are constraining the entire flow. The process for doing this and the effectiveness are documented in Goldratt’s “Theory of
Constraints” (TOC). The TOC states that the entire system is constrained
by one constraint and improvement of the system will only be effective once that constraint is resolved.
Subordinate everything else to the above decisions.
Elevate the constraint.
If, in the previous steps, a constraint has been broken, go
back to step one but do not allow the inertia to cause a system constraint.
Some common constraints are:
Resource Constraints - resources such as the number of people who can perform the task, access to environments, etc. which
block the flow based on its limited capacity for the desired outcomes.
Policy Constraints - policies, practices or metrics that artificially impede flow due to their poor alignment with the overall performance of the system.
Working daily to relentlessly remove constraints is the most important work a team can do. Doing so means they are constantly
testing their improved delivery system by delivering value and constantly improving their ability to do so. Quality, predictability,
stability, and speed all improve.
Metrics are key to organizational improvement. If we do not measure, then any attempt at improvement is aimless.
Metrics, like any tool, must be used correctly to drive the improvement we need. It’s important to use metrics in
offsetting groups and to focus improvement efforts on the group of metrics as a whole, not as individual measures.
The Metrics Cheat Sheet has a high-level view of the key metrics, their intent, and how to
use them appropriately.
CD Execution
When measuring the performance of continuous delivery, we are measuring our ability to reliably and sustainably deliver high-quality changes. We do this by focusing on very frequent small batches of high-quality delivery.
Change frequency is important to make sure that waste is driven out of the process. This reduces costs, improves the
sustainability of flow, and ensures there is a verified quality process for emergency changes.
Small batches are easier to inspect for quality and limit the impact of any quality issues.
Change success is an important offsetting metric. If we only focus on change size and change frequency,
quality will suffer. If we only focus on reducing the number of defects and eliminating impacting changes, batch size
and frequency suffer. The data shows that this results in more defects and more costs.
Throughput
Development Cycle Time: Time from when a task is started until it is “Done”. The
suggested definition of “Done” is delivered to production. KPI for how big a unit of work is. Indicator of
possible upstream quality issues with requirements definition and teamwork.
Delivery Frequency: KPI for batch size, cost, and efficient quality process.
Stability
Change Failure Rate: Percentage of changes that require remediation. KPI for the effectiveness of the quality process.
Defect Rate: Rate of defect creation over time relative to change frequency, generally P1 and P2.
Mean Time to Repair: KPI for the maturity of our disaster response preparations and
the forethought to design for recovery instead of just for delivery.
CI Execution
Continuous delivery stands on the bedrock of continuous integration. If code is not continuously integrating, it cannot
be safely delivered.
The focus of CI is to amplify quality feedback. The more frequently code is integrated and tested, the sooner any
quality issues will be found and the smaller those issues will be.
Integration Frequency: Frequency of code integrating to the trunk. KPI for efficacy of
refining requirements, quality process, and teamwork.
When a team is mob programming, this should occur several times a day.
When a team is pair programming, this should occur several times a day per pair.
When the team is working on individual tasks, this should occur several times a day per developer.
Build Cycle Time: Time from commit to production deploy. KPI for the stability of the
pipeline and efficiency of the quality process. Long build cycle times have a direct negative impact on MTTR, and
batch size. This encourages abandoning defined quality checks in emergencies. This makes emergency changes the
riskiest changes to make.
Workflow Management
Velocity / Throughput: Planning metric to allow the team to predict date ranges for delivery. The
standard deviation of this metric is a KPI for predictability. The average value of the metric has no meaning outside
the team.
Lead Time: Total time from when a request is made until it is delivered. KPI for team over-utilization
As the team’s utilization approaches 100%, this metric approaches infinity.
Work In Process (WIP): Key flow metric. Excessive WIP results in rework and delivery delays
3.1 - Metrics Cheat Sheet
Organizational Metrics
These metrics are important for teams and management to track the health of the delivery system
Time from when a story is started until marked “done”
Reduce the size of work to improve the feedback from the end user on the value of the work and to improve the quality of the acceptance criteria and testing
The number of items in progress on the team relative to the size of the team
Reduce the number of items in progress so that the team can focus on completing work vs/ being busy.
Delivery frequency should not degrade
Team Metrics
These metrics should only be used by teams to inform decision making. They are ineffective for measuring quality, productivity, or
delivery system health.
The average amount of the backlog delivered during a sprint by the team. Used by the product team for planning. There is no such thing as good or bad velocity.
3.2 - Average Build Downtime
The average length of time between when a build breaks and when it is fixed.
What is the intended behavior?
Keep the pipelines always deployable by fixing broken builds as rapidly as possible. Broken builds are the highest priority since
they prevent production fixes from being deployed in a safe, standard way.
How to improve it
Refactor to improve testability and modularity.
Improve tests to locate problems more rapidly.
Decrease the size of the component to reduce complexity.
Add automated alerts for broken builds.
Ensure the proper team practice is in place to support each other in solving the problem as a team.
How to game it
Re-build the previous version.
Remove tests that are failing.
Guardrail Metrics
Metrics to use in combination with this metric to prevent unintended consequences.
Integration Frequency decreases as additional manual or automated process overhead is
added before integration to trunk.
3.3 - Build Cycle Time
The time from code commit to production deploy. This is the minimum time changes can be applied to production. This is
referenced as “hard lead time” in Accelerate
What is the intended behavior?
Reduce pipeline duration to improve MTTR and improve test efficiency to
give the team more rapid feedback to any issues. Long build cycle times delay quality feedback
and create more opportunity for defect penetration.
How to improve it
Identify areas of the build that can run concurrently.
Replace end to end tests in the pipeline with virtual services and move end to end testing to an asynchronous process.
Break down large services into smaller sub-domains that are easier and faster to build / test.
Add alerts to the pipeline if a maximum duration is exceeded to inform test refactoring priorities.
How to game it
Reduce the number of tests running or test types executed.
Guardrail Metrics
Metrics to use in combination with this metric to prevent unintended consequences.
Defect rates increase if quality gates are skipped to reduce build time.
3.4 - Change Fail Rate
The percentage of changes that result in negative customer impact, or rollback.
changeFailRate = failedChangeCount / changeCount
What is the intended behavior?
Reduce the percentage of failed changes.
How to improve it
Release more, smaller changes to make quality steps more effective and reduce the impact of failure.
Identify root cause for each failure and improve the automated quality checks.
How to game it
Deploy fixes without recording the defect.
Create defect review meetings and re-classify defects as feature requests.
Re-deploy the latest working version to increase deploy count.
Guardrail Metrics
Metrics to use in combination with this metric to prevent unintended consequences.
Delivery frequency can decrease if focus is placed on “zero defect” changes.
Defect rates can increase as reduced delivery frequency increases code change batch size and delivery risk.
A measure of the amount of code that is executed by test code.
What is the intended behavior?
Inform the team of risky or complicated portions of the code that are not sufficiently covered by tests. Care should be
taken not to confuse high coverage with good testing.
How to improve it
Write tests for code that SHOULD be covered but isn’t
Refactor the application to improve testability
Remove unreachable code
Delete pointless tests
Refactor tests to test behavior rather than implementation details
How to game it
Tests are written for code that receives no value from testing.
Test code is written without assertions.
Tests are written with meaningless assertions.
Example: The following test will result in 100% function, branch, and line coverage with no behavior tested.
/* Return the sum of two integers *//* Return null if one of that parms is not an integer */functionaddWholeNumbers(a,b){if(a%1===0&&b%1===0){returna+b;}else{returnnull;}}it('Should not return null of both numbers are integers'()=>{/*
* This call will return 4, which is not null.
* Pass
*/expect(addWholeNumbers(2,2)).not.toBe(null);/*
* This returns "22" because JS sees a string will helpfully concatenate them.
* Pass
*/expect(addWholeNumbers(2,'2')).not.toBe(null);/*
* The function will never return the JS `NaN` constant
* Pass
*/expect(addWholeNumbers(1.1,0)).not.toBe(NaN);})
The following is an example of test code with no assertions. This will also produce 100% code coverage reporting but does not test anything because there are no assertions to cause the test to fail.
it('Should not return null if both numbers are integers'()=>{addWholeNumbers(2,2);addWholeNumbers(2,'2');addWholeNumbers(1.1,0);})
Guardrail Metrics
Test coverage should never be used as a goal or an indicator of application health. Measure outcomes. If testing is poor, the following metrics will show poor results.
Defect Rates will increase as poor-quality tests are created to meet coverage targets that do not reliably catch defects.
Development Cycle Time will increase as more emphasis is placed on improper testing methods (manual functional testing, testing teams, etc.) to overcome the lack of reliable tests.
3.6 - Code Integration Frequency
The average number of production-ready pull requests a team closes per day, normalized by the number of developers on
the team. On a team with 5 developers, healthy CI practice is
at least 5 per day.
What is the intended behavior?
Increase the frequency of code integration
Reduce the size of each change
Improve code review processes
Remove unneeded processes
Improve quality feedback
How to improve it
Decompose code changes into smaller units to incrementally deliver features.
The lines of code that have been changed but have not been delivered to production. This can be measured at several points in the
delivery flow, starting with code not merged to trunk.
What is the intended behavior?
Reduce the size of individual changes and reduce the duration of branches to improve quality feedback. We also want to
eliminate stale branches that represent risk of lost change or merge conflicts that result in additional
manual steps that add risk.
How to improve it
Improve continuous integration behavior where changes are integrated to the trunk and
verified multiple times per day.
How to game it
Use forks to hide changes.
Guardrail Metrics
Metrics to use in combination with this metric to prevent unintended consequences.
Quality can decrease as quality steps are skipped or batch size increases.
3.8 - Defect Rate
Defect rates are the total number of defects by severity reported for a period of time.
Defect count / Time range
What is the intended behavior?
Use defect rates and trends to inform improvement of upstream quality processes.
Defect rates in production indicate how effective our overall quality process is. Defect rates in lower environments inform us of
specific areas where quality process can be improved. The goal is to push detection closer to the developer.
How to improve it
Track trends over time and identify common issues for the defects Design test design changes that would reduce the time
to detect defects.
How to game it
Mark defects as enhancement requests
Don’t track defects
Deploy changes that do not modify the application to improve the percentage
Guardrail Metrics
Metrics to use in combination with this metric to prevent unintended consequences.
Delivery frequency is reduced if too much emphasis is place on zero defects. This can be
self-defeating as large change batches will contain more defects.
3.9 - Delivery Frequency
How frequently per day the team releases changes to production.
What is the intended behavior?
Small changes deployed very frequently to exercise the ability to fix production
rapidly, reduce MTTR, increase quality, and reduce risk.
This shows the average time it takes for a new request to be delivered. This is
measured from the creation date to release date for each unit of work and includes Development Cycle Time.
What is the intended behavior?
Identify over utilized teams, backlogs that need more Product Owner attention,
or in conjunction with velocity to help teams optimize their processes.
How to improve it
Relentlessly remove old items from the backlog.
Improve team processes to reduce Development Cycle Time.
Use Innersourcing to allow other teams to help when surges of work arrive.
Re-assign, carefully, some components to another team to scale delivery.
How to game it
Requests can be tracked in spreadsheet or other locations and then added to
the backlog just before development. This can be identified by decreased
customer satisfaction.
Reduce feature refining rigour.
Guardrail Metrics
Metrics to use in combination with this metric to prevent unintended consequences.
Quality is reduced if less time is spent refining and defining
testable requirements.
Mean Time to Repair is the average time between when a incidents is
detected and when it is resolved.
“Software delivery performance is a combination of three metrics: lead time, release
frequency, and MTTR. Change fail rate is not included, though it
is highly correlated.”
Quality is measured as the percentage of finished work that is unused, unstable, unavailable, or defective according to the end user.
What is the intended behavior?
Continuously improve the quality steps in the construction process, reduce the size of delivered change, and increase
the speed of feedback from the end user. Improving this cycle improves roadmap decisions.
How to improve it
Add automated checks to the pipeline to prevent re-occurrence of root causes.
Only begin new work with testable acceptance criteria.
Accelerate feedback loops at every step to alert to quality, performance, or availability issues.
How to game it
Log defects as new features
Guardrail Metrics
Metrics to use in combination with this metric to prevent unintended consequences.
[Delivery frequency may be reduced if more manual quality steps are added
Build cycle time may increase as additional tests are added to the pipeline
Lead time can increase as more time is spent on business analysis
3.14 - Velocity / Throughput
The average amount of the backlog delivered during a sprint by the team. Used by the product team for planning. There is no such thing as good or bad velocity. This is commonly misunderstood to be a productivity metric. It is not.
What is the intended behavior?
After a team stabilizes, the standard deviation should be low. This will enable realistic planning of future
deliverables based on relative complexity. Find ways to increase this over time by reducing waste, improving planning,
and focusing on teamwork.
How to improve it
Reduce story size so they are easier to understand and more predictable.
Minimize hard dependencies. Each hard dependency reduces the odds of on-time
delivery by 50%.
Swarm stories by decomposing them into tasks that can be executed in parallel so that the team is working as a unit to deliver faster.
How to game it
Cherry pick easy, low priority items.
Increase story points
Skip quality steps.
Prematurely sign-off work only to have defects reported later.
Guardrail Metrics
Metrics to use in combination with this metric to prevent unintended consequences.
Quality defect ratio goes up as more defects are reported.
WIP increases as teams start more work to look more
busy.
Work in Progress (WIP) is the total work that has been started but not
completed. This includes all work, defects, tasks, stories, etc.
What is the intended behavior?
Focus the team on finishing work and delivering it rather than switching between tasks but not finishing them.
How to improve it
The team should focus on finishing items closest to being ready for
production.
Prioritize code review over starting new work
Prioritize pairing to solve a problem over starting new work
Set and do not exceed WIP limits for the team.
Total WIP should not exceed team size.
Keep the Kanban board visible at all times to monitor WIP
How to game it
Update incomplete work to “done” before it is delivered to production.
Create stories for each step of development instead of for value to be delivered.
Do not update work to “in progress” when working on it.
4 - Team Workflow
Working together as a team is how we move things from “In Progress” to “Done”, as rapidly as possible in value sequence. It’s important for minimizing WIP that the team looks at the backlog as the team’s work and does not pre-assign work to individuals.
Make Work Visible
To create and maintain the flow of delivery, we need the following:
A way to visualize the workflow, virtual or physical, with a
prioritized backlog that has not been refined too far in the future.
Plan Work
Unplanned work is anything coming into the backlog that has not been committed
to, or prioritized. This can include feature requests, support tickets, etc.
Common struggles teams face with unplanned work can be:
Completed work meets the Definition of Ready
when work begins, the Definition of Done when work
is delivered, and can be completed in less than two days.
Process smells identified for completing work include:
Context switching
Ineffective demos that prevent early feedback
Multiple teams own pieces of the process (Build, Test, Deploy, etc.)
In order to plan and complete work effectively, there must be an improvement
process in place. The improvement process is centered around feedback loops.
Challenges associated with the improvement process:
Use the right pattern for the right reason. Branches are the primary flow for CI
and are critical for allowing the team to have visibility to work in progress that the team is responsible for completing. Forks
are how proposed, unplanned changes are made from outside the team to ensure quality control and to reduce confusion from
unexpected branches.
Use forks for:
Contribution from a contributor outside the team to ensure proper quality controls are followed and to prevent
cluttering up the team’s repository with external contributions that may be abandoned.
Use branches for:
All internal work to keep that work visible to the team.
Tips
Story Slicing helps break
development work into more easily consumable, testable chunks.
You don’t have to wait for a story/feature to be complete as long as you have tested
that won’t break production.
Pull requests should be small and should be prioritized over starting any new development.
Common Issues
Trunk-based development and continuous integration often take workflow adjustments on the team.
The main reasons teams struggle with CI are:
Delivery and quality are significantly impacted by teams sharing
ownership of the source code. This adds process overhead to ensure everyone knows
what’s happening in the code and dilutes quality responsibility.
Recommended Practices
Utilize automated pipelines to help validate that the product remains releasable before and after any code is merged to the trunk.
Limit ownership of a repository to a single “Two Pizza Team” that decides what code to merge.
Give all developers on the team access to merge code to the trunk. Give read access to everyone else.
Use an innersourcing policy so that people outside of the team know how to contribute to your product.
Tips
Teams looking to create an InnerSourcing policy can start by applying their Definition of Done to any external contributions.
No contributions will bypass the team’s quality process.
Automated pipelines validate that PRs from internal and external contributors conform to quality standards.
All team members have access to merge to the trunk.
InnerSourcing and/or external contributions fork the repository they do not branch.
Teams no larger than 10 people, including all roles.
All teams need a Definition of Done. The Definition of Done is an agreement made between the team
that a unit of work isn’t complete without meeting certain conditions.
Recommended Practices
We use the Definition of Done most commonly for user stories. The team and
product owner must agree that the story has met all criteria for it to be
considered done.
A definition of done can include anything a team cares about, but must include
these criteria:
All tests passed
All acceptance criteria have been met
Code reviewed by team member and merged to trunk
Demoed to team/stakeholders as close to prod as possible
All code associated with the acceptance criteria deployed to production
Once your team has identified all criteria that a unit of work needs to be
considered done, you must hold yourself accountable to your Definition of Done.
Value
As a development team, we want to understand our team’s definition of done, so
that we can ensure a unit of work is meeting the criteria acceptable for it to
be delivered to our customers.
Acceptance Criteria
Identify what your team cares about as a Definition of Done.
Use your Definition of Done as a tool to ensure quality stories are being
released into production.
Revisit and evaluate your Definition of Done.
4.5 - Retrospectives
Retrospectives are critical for teams that are serious about continuous
improvement. They allow the team an opportunity to take a moment to inspect and
adapt how they work. The importance of this cannot be overstated. Entropy is
always at work, so we must choose to change so that change doesn’t choose us.
Recommended Practices
Successful Retrospectives
A successful retrospective has five parts:
Go over the mission of the team and the purpose of retrospective.
The team owns where they are right now using Key Performance Indicators
(KPIs) they’ve agreed on as a team.
The team identifies whether experiments they are running are working or not.
If an experiment is working, the team works to standardize the changes as
part of daily work.
If an experiment is not working, the team either adjusts the experiment
based on feedback or abandons the experiment to try something else.
Both are totally acceptable and expected results. In either case, the
learnings should be shared publicly so that anyone in the organization can
benefit from them.
The team determines whether they are working towards the right goal and
whether the experiments they are working on are moving them towards it.
If answer to either of the questions is “No.” then the team adjusts as necessary.
Open and honest conversation about wins and opportunities throughout.
Example Retro Outline
Go over the team’s mission statement and the purpose of retrospective (2 min)
Go over the team’s Key Performance Indicators and make sure everyone knows
where we are (5-10 min)
Go over what experiments the team decided to run and what we expected to
happen (5 minutes)
What did we learn this week? (10-15 minutes)
Should we modify any team documents? (2 minutes)
What went well this week? (5-10 minutes)
What sinks our battleship? (5-10 minutes)
Are we working towards the right things? What are we going to try this week?
How will we measure it? (10-15 minutes)
Organizing Retros
There are some important things to consider when scheduling a retrospective.
Ensure Psychological Safety
If the team feels like they can’t speak openly on honestly, they won’t.
Any issues with psychological safety must be addressed before any real
progress can be made.
Make them Regular
Agree to a time, day, frequency as a team to meet.
Include everyone responsible for delivery
Ideally this will include business colleagues (PO), operations, testing,
and developers involved in the process.
If there are more than 10-12 people in the meeting, your team is
probably too big.
Co-location concerns
If the team is split across timezones, then accommodations
should be made so that the team can effectively communicate.
If the time separation is extreme (i.e. India/US), then in may be better
to have each hemisphere retro separately and compare notes
asynchronously.
Schedule meetings to be inclusive of the most remote. Don’t schedule rooms
with bad audio/no video if there are remote participants. Have it via a
remote meeting solution (Zoom, etc.)
Tips
Create cards on whatever board you are using to track your work for action
items that come out of retrospective
Treating team improvement as a deliverable will help the team treat them
more seriously.
Do not work on more than a few actions/experiments at a time
If the retrospective has remote attendees, ask that everyone turn on their
cameras so that the team can look everyone in the eyes.
Outcome over output: If the format of retro isn’t helping you improve, change
it or seek help on how to make it better. The teams that cancel retro are
almost always the teams that need it most.
Known Impediments
“Typical” Retrospectives
Normally, a scrum-like retro involves 3 questions about the previous iteration:
What went well?
What could we improve?
What are some actions we can take?
This is pretty open ended format that is very simple to go over in a training
class. The challenge is the nuance of facilitating the format.
While it can be effective, what we have found is that this particular format can
actually stunt the improvement of many teams when used incorrectly. And since
the format is so open ended, that’s extremely easy to do.
Retrospectives that follow the above format are something that many teams
struggle with. They can…
Feel Ineffective, where the same issues crop up again and again without resolution.
End with a million action items that never get done or tracked.
“Improve” things that don’t actually move the needle on team productivity or happiness
End up as a gripe session where there are no actionable improvements identified.
This is such a waste of time. I'd rather be coding...
It can be extremely frustrating to team members when it feels like
retrospectives are just another meeting that they have to go to. If that ever
becomes the case, that should signal a huge red flag! Something is wrong!
Psychological Safety
If the team feels like they are going to be judged, punished, or generally
negatively affected by participating in retrospective, then they are going to
keep their opinions to themselves. Without the safety to have their voices heard
or take moderate, hypothesis driven, risk, the team will not improve as fast as
they can (if at all).
However, if leadership feels like they are being disrespected, they aren’t being
listened to/considered, or feel like they are going to be negatively impacted by
the outcomes of the team they are more likely to restrain a team from their full
potential.
It’s a delicate balancing act that takes trust, respect, and empathy from all
sides to come to win-win solutions.
4.6 - Unplanned Work
Unplanned work is any interruption that prevents us from finishing something as planned. There are times when unplanned work is necessary and understandable, but you
should be wary of increased risk, uncertainty, and reduced predictability.
Cost of Delay
Work that has not been prioritized is work that has not been planned. When there are
competing features, requests, support tickets, etc., it can be difficult to prioritize
what should come first.
Most of the time, teams prioritize based on what the customer wants, what the
stakeholders want, etc.
Cost of Delay makes it easier to decide priorities based on value and urgency. How much money are we costing (or saving) the organization if Feature A is
delivered over Feature B?
Capacity Planning
The most common pitfall that keeps teams from delivering work is unrealistic
capacity planning.
Teams that plan for 100% of their capacity are unable to fit unknowns
into their cadence, whether that be unplanned work, spikes, or continuous experimentation
and learning.
Planned capacity should fall between 60% and 80% of a team’s max capacity.
Tips
Plan for unplanned work. Pay attention to the patterns that present themselves, and analyze
what kind of unplanned work is making it to your team’s backlog.
Make work visible, planned and unplanned, and categorize unplanned work based on value and urgency.
4.7 - Visualizing Workflow
Making work visible to ourselves, as well as our stakeholders is imperative in
our workflow management process. People are visual beings. Workflows give
everyone a sense of ownership and accountability.
Make use of a Kanban board
Kanban boards help you to make work and problems visible and improve workflow
efficiency.
Kanban boards are a recommended practice for all agile development methods. Kanban signals your availability to do work. When an individual pulls
something from the backlog into progress, they are committing to being
available to do the work the card represents.
With Kanban boards, your team knows who’s working on what, what the status of
that work is, and how long that work has been in progress.
Building a Kanban Board
To make a Kanban board you need to create lanes on your board that represent
your team’s workflow. Adding work in progress (WIP) limits to swim-lanes will
enhance the visibility of your team’s workflow.
The team only works on cards that are in the “Ready to Start” lane and
team members always pick from the top. No “Cherry Picking”.
The following is a good starting point for most teams.
Backlog
Ready to Start
Development
Ready to Review
Blocked
Done
Tips
Track everything:
Stories, tasks, spikes, etc.
Improvement items
Training development
Extra meetings
Work is work, and without visibility to all of the team’s work it’s impossible to identify and reduce the waste created by unexpected work.
Bring visibility to dependencies across teams, to help people anticipate
what’s headed their way, and prevent delays from unknowns and invisible work.
Work in Progress is defined as work that has started but is not yet finished. Limiting WIP helps teams reduce context switching, find workflow issues, and keep teams focused on collaboration and finishing work.
How do we limit WIP?
Start with one lane on your board.
Set your WIP limit to N+2 (“N” being the number of people contributing to that lane)
Continue setting WIP lower.
Once the WIP limit is reached, no more cards can enter that lane until one exits.
Capacity Utilization
There is a direct correlation between WIP and capacity utilization.
Attempting to load people and resources to 100% capacity utilization creates
wait times. Unpredictable events equal variability, which equals capacity overload.
The more individuals and resources used, the higher the cost and risk.
In order to lessen work in progress, be aggressive in prioritization, push
back when necessary, and set hard WIP limits. Select a WIP limit that is
doable but challenges you to say no some of the time.
Conflicting Priorities
When we start a new task before finishing an older task, our work in
progress goes up and things take longer. Business value that could have been
realized sooner gets delayed because of too much WIP.
Be wary of falling back into the old habit of starting everything because of
the pressure to say yes to everything.
Look at priority ways of working:
Assigned priority
Cost of delay
First-in, first-out
Tips
Swarming Stories
Having more than one person work on a task at the same time avoids situations
where team understanding is mostly limited to a subset of what’s being built.
With multiple people involved early, there is less chance that rework will
be needed later.
By having more than one developer working on a task, you are getting a
real-time code review.
There are common patterns to show how much of each kind of test is generally recommended. The most used are the Test Pyramid and the Test Trophy. Both are trying to communicate the same thing: design a test suite that is fast, gives you confidence, and is not more expensive to maintain than the value it brings.
Testing Principles
Balance cost and confidence
Move failure detection as close to the developer as possible
Increase the speed of feedback
CI to take less than 10 minutes.
Recommended Test Pattern
Most of the tests are integration tests and emphasize maximizing deterministic test coverage in process with the development cycle, so developers can find errors sooner. E2E & functional tests should primarily focus on happy/critical path and tests that absolutely require a browser/app.
When executing continuous delivery, test code is a first class citizen that requires as much design and maintenance as production code. Flakey tests undermine confidence and should be terminated with extreme prejudice.
Testing Matrix
Feature
Static
Unit
Integration
Functional
Visual Regression
Contract
E2E
Deterministic
Yes
Yes
Yes
Yes
Yes
No
No
PR Verify, Trunk Verify
Yes
Yes
Yes
Yes
Yes
No
No
Break Build
Yes
Yes
Yes
Yes
Yes
No
No
Test Doubles
Yes
Yes
Yes
Yes
Yes
See Definition
No
Network Access
No
No
localhost only
localhost only
No
Yes
Yes
File System Access
No
No
No
No
No
No
Yes
Database
No
No
localhost only
localhost only
No
Yes
Yes
Testing Anti-patterns
“Ice cream cone testing” is the anti-pattern where the most expensive, fragile, non-deterministic tests are prioritized over faster and less expensive deterministic tests because it “feels” right.
Testing terms and they are notoriously overloaded. If you ask 3 people what integration testing means you will get 4 different answers. This ambiguity within an organization slows down the engineering process as the lack of ubiquitous language causes communication errors. For us to help each other improve our quality processes, it is important that we align on a common language. In doing so, we understand that many may not agree 100% on the definitions we align to. That is ok. It is more important to be aligned to consensus than to be 100% in agreement. We’ll iterate and adjust as needed.
Note: Our definitions are based on the following sources:
A deterministic test is any test that always returns the same results for the same beginning state and action. Deterministic tests should always be able to run in any sequence or in parallel. Only deterministic tests should be executed in a CI build or automatically block delivery during CD.
Non-deterministic Test
A non-deterministic test is any test that may fail for reasons unrelated to adherence to specification. Reasons for this could include network instability, availability of external dependencies, state management issues, etc.
Static Test
A static test is a test that evaluates non-running code against rules for known good practices to check for security, structure, or practice issues.
Unit Test
Unit tests are deterministic tests that exercise a discrete unit of the application, such as a function, method, or UI component, in isolation to determine whether it behaves as expected.
An integration test is a deterministic test to verify how the unit under test interacts with other units without directly accessing external sub-systems. For the purposes of clarity, “integration test” is not a test that broadly integrates multiple sub-systems. That is an E2E test.
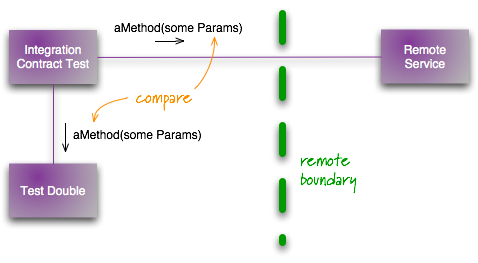
A contract test is used to validate the test doubles used in a network integration test. Contract tests are run against the live external sub-system and exercises the portion of the code that interfaces to the sub-system. Because of this, they are non-deterministic tests and should not break the build, but should trigger work to review why they failed and potentially correct the contract.
A contact test validates contract format, not specific data.
A functional test is a deterministic test that verifies that all modules of a sub-system are working together. They should avoid integrating with other sub-systems as this tends to reduce determinism. Instead, test doubles are preferred. Examples could include testing the behavior of a user interface through the UI or testing the business logic of individual services through the API.
End to end tests are typically non-deterministic tests that validate the software system along with its integration with external interfaces. The purpose of end-to-end Test is to exercise a complete production-like scenario. Along with the software system, it also validates batch/data processing from other upstream/downstream systems. Hence, the name “End-to-End”. End to End Testing is usually executed after functional testing. It uses actual production like data and test environment to simulate real-time settings.
Customer Experience Alarms are a type of active alarm. It is a piece of software that sends requests to your system much like a user would. We use it to test the happy-path of critical customer workflows. These requests happen every minute (ideally, but can be as long as every 5 minutes). If they fail to work, or fail to run, we emit metrics that cause alerts. We run these in all of our environments, not just production, to ensure that they work and we catch errors early.
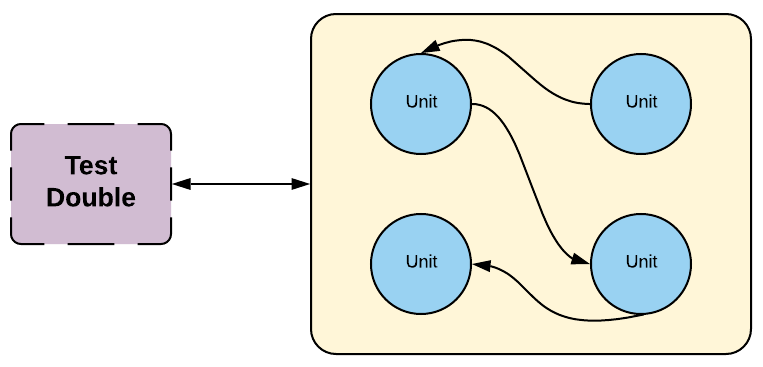
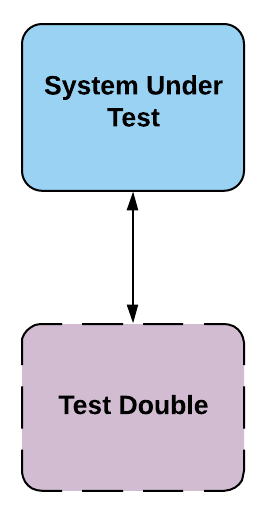
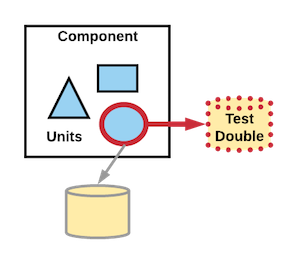
Test doubles are one of the main concepts we use to create fast, independent, deterministic and reliable tests. Similar to the way Hollywood uses a _stunt double* to film dangerous scenes in a movie to avoid the costly risk a high paid actor gets hurt, we use a test double in early test stages to avoid the speed and dollar cost of using the piece of software the test double is standing in for. We also use test doubles to force certain conditions or states of the application we want to test. Test doubles can be used in any stage of testing but in general, they are heavily used during the initial testing stages in our CD pipeline and used much less in the later stages. There are many different kinds of test doubles such as stubs, mocks, spies, etc.
Lower cost to maintain, faster speed to execute, less time to develop, confidence, stability
Use Case Coverage
One of the main points behind testing is to be able to code with confidence. Code coverage is one way developers have traditionally used to represent how confident they feel about working on a given code base. That said, how much confidence is needed will likely vary by team and the type of application being tested. E.g. if working on a life saving med tech piece of software, you probably want all of the confidence in the world. The following discusses how code coverage, if misused, can be misleading and create a false sense of confidence in the code being worked on and as a result, hurt quality. Recommendations on how to manage code coverage in a constructive way will be presented, along with concrete approaches on how to implement them.
In simple terms, coverage refers to a measurement of how much of your code is executed while tests are running. As such, it’s entirely possible achieve 100% coverage by running through your code without really testing for anything, which is what opens the door for coverage having the potential of hurting quality if you don’t follow best practices around it. A recommended practice is to look at coverage from the perspective of the set of valid use cases supported by your code. For this, you would follow an approach similar to what follows:
Start writing code and writing tests to cover for the use cases you’re supporting with your code.
Refine this by going over the tests and making sure valid edge cases and alternative scenarios are covered as well.
When done, look at your code’s coverage report and identify gaps in your testing
For each gap, decide if the benefit of covering it (odds of it failing and impact if it does) outweighs the cost (how complicated / time consuming would it be to cover it)
Write more tests where appropriate
This practices shifts the value of coverage from being a representation of your code’s quality to it being a tool for finding untested parts of your code. When looking at coverage through this lens, you might also uncover parts of the code with low coverage because it’s not supporting a valid use case. We recommend tests are not written for this, instead this code should be removed from the code base if at all possible.
You might ask yourself “How do I know I have good coverage? What’s the magic number?”. We believe there’s no magic number, as it’ll all depend on your teams’ needs. If you are writing tests for the use cases you build into your application, your team feels very confident when modifying the code base, and you’re post-production error rate is very low, your coverage is probably fine, whatever the numbers say. In the end, forcing a coverage percentage is known to have the potential of hurting your quality. By chasing after every single code path, you can very well end up missing the use cases that if gone wrong, will hurt the most. Another consideration is the false sense of confidence you can get by high coverage numbers obtained by “gaming the system”, or as Martin Fowler said, “The trouble is that high coverage numbers are too easy to reach with low quality testing” (Fowler, 2012). We do recognize there is such a thing as too little coverage. If your coverage is very low (e.g. < 50%) there might be something off, like having a ton of unnecessary code you might want to get rid of, or your tests just not hitting all the critical use cases in your application. There are methods you can employ to make sure there are no instances of “gaming the system” in your test code. One of these is to create linting rules that look for these practices and fail the build when it finds them. We recommend using plugins like eslint-plugin-jest to make sure things like not expecting (asserting) or disabling of tests cause the build to break.
Another recommendation when managing your code coverage is to track when it goes down. Generally it shouldn’t and if / when it does, it should be explainable and trigger a build failure. Along this same line, raising the bar whenever coverage is increased is a good practice as it ensures the level of coverage in other areas is maintained as they were. We recommend automating this so that whenever your coverage percentage increases, so do your minimum thresholds. Once you have reached a certain level of coverage through the methods discussed above (e.g. covering for use cases, taking care of valid edge cases when appropriate, etc) we don’t recommend you actively work on increasing your code coverage percentages. Instead, the way we recommend coverage to go up is as a side effect of building good software. This means that, as you increase your delivery frequency while monitoring your key stability metrics (e.g post-production defects, performance or service degradations, etc) you should see your code coverage increase.
Test-First Approach: BDD and TDD
Defining tests prior to writing code is the best way to lock in behavior and produce clean code. BDD and TDD are complementary processes to accomplish this goal and we recommend teams use both to first uncover requirements (BDD) and then do development against these requirements (TDD).
BDD
Behavior Driven Development is the process of defining business requirements as testable acceptance criteria and then implementing them using a test-first development approach. Examples and references for BDD can be found in the playbook on BDD.
When coding tests, the test statements should clearly describe what is being executed so that we can create a shared understanding of what’s getting build by all stakeholders. Tests are the living documentation for what the application is doing and test results should be effective on-boarding documentation.
TDD
Test-driven development is the practice of writing a failing test before the implementation of a feature or bug fix. Red -> Green -> Refactor refers to the TDD process of adding a failing (red) test, implementing that failing test to make it pass (green) and then cleaning up the code after that (refactor). This approach to testing gives you confidence as it avoids any false positives and also serves as a design mechanism to help you write code that is decoupled and free of unnecessary extra code. TDD also drives up code coverage organically due to the fact that each use case gets a new test added.
People often confuse writing tests in general with TDD. Writing tests after implementing a use case is not the same as TDD, that would be test oriented application development (TOAD) and like a toad, it has many warts. The process for toad would be green, green then refactor at a later date, maybe. The lack of a failing test in that process opens the door for false positive tests and often ends up taking more time as the code and tests end up needing to both be refactored. In addition, the design of an api is not considered as things are developed from the bottom up, not from the top down. This can lead to tight coupling, unnecessary logic and other forms of tech debt in the codebase.
Naming Conventions
Test names should generally be descriptive and inclusive of what is being tested. A good rule of thumb when deciding a test name is to follow the “given-when-then” or “arrange-act-assert” conventions focusing on the “when” and “act” terms respectively. In both of these cases there is an implied action or generalized assertion that is expected, a test name should include this implication explicitly with an appropriate result effect description. For example:
// Jest Example
// "input validator with valid inputs should contain a single valid field caller receives success state"
describe("input validator",()=>{describe("with valid inputs",()=>{it("should contain a single valid field caller receives success state",()=>{});});});
// JUnit Example// "input validator with valid inputs should contain a single valid field caller receives success state"@DisplayName("input validator")publicclassInputValidationTest{@Nested@DisplayName("with valid inputs")classValidScenarios{@Test@DisplayName("should contain a single valid field caller receives success state")publicvoidcontainsSingleValidField(){// }}}
Casing
For test environments that require method names to describe its tests and suites it is recommended that they follow their language and environment conventions. See formatting under static testing for further best practices.
Grouping
Where possible suites and their respective tests should be grouped to allow for higher readability and identification; If the environment supports it nested groups is also a useful and good practice to employ. For example a logical nesting of “unit-scenario-expectation” allows for encapsulating multiple scenarios that could potentially apply to a unit under test. For example:
Prevent common anti-patterns like disabling, skipping, or commenting test cases or coverage gathering
Make sure it’s still covering for valid use cases
A contract test is used to validate the test doubles used in a network integration test. Contract tests are run against the live external sub-system and exercises the portion of the code that interfaces to the sub-system. Because of this, they are non-deterministic tests and should not break the build, but should trigger work to review why they failed and potentially correct the contract.
A contract test validates contract format, not specific data.
Contract tests have two points of view, Provider and Consumer.
Provider
Providers are responsible for validating that all API changes are backwards compatible unless otherwise indicated by changing API
versions. Every build should validate the API contract to ensure no unexpected changes occur.
Consumer
Consumers are responsible for validating that they can consume the properties they need (see Postel’s Law) and that no change
breaks their ability to consume the defined contract.
Recommended Best Practices
Provider contract tests are typically implemented as unit tests of the schema and response codes of an interface. As such they should be deterministic and should run on every commit, pull request, and verification of the trunk.
Consumer contract tests should avoid testing the behavior of a dependency, but should focus on comparing that the contract double still matches the responses from the dependency. This should be running on a schedule and any failures reviewed for cause. The frequency of the test run should be proportional to the volatility of the interface.
When dependencies are tightly aligned, consumer-driven contracts should be used
The consuming team writes automated tests with all consumer expectations
They publish the tests for the providing team
The providing team runs the CDC tests continuously and keeps them green
Both teams talk to each other once the CDC tests break
Provider Responsibilities:
Providers should publish machine-readable documentation of their interface to facilitate consumer testing and discoverability.
Even better, publish a dedicated technical compatibility kit that is tested on every build that provides a trusted virtual service to eliminate the need for consumer contract testing.
End to end tests are typically non-deterministic tests that validate the software system along with its integration with external interfaces. The purpose of end-to-end Test is to exercise a complete production-like scenario. Along with the software system, it also validates batch/data processing from other upstream/downstream systems. Hence, the name “End-to-End”. End to End Testing is usually executed after functional testing. It uses actual production like data and test environment to simulate real-time settings
End to end tests have the advantage of exercising the system in ways that functional tests cannot. However, they also have
the disadvantage of being slower to provide feedback, require more state management, constant maintenance, and can fail for reasons unrelated to code defects. As such, it is recommended
that they be the smallest number of tests executed.
End-to-end tests are segmented into two categories: vertical and horizontal tests.
Vertical E2E Tests
Vertical tests are end to end tests which target features under the control of a single team. Examples of these may be “when I click the heart icon on an item, it’s favorited and that persists across a refresh” or “a user can create a new saved list and add items to it”.
Horizontal E2E Tests
A horizontal test, by contrast, spans multiple teams. An example of this may be going from the homepage through checkout. That involves coordination across the homepage, item page, cart, and checkout teams.
Because of the inherent complexity of horizontal tests (multi-team), they are unsuitable for blocking release pipelines.
Recommended Best Practices
E2E tests should be the least used due to their cost in run time and in maintenance required.
Focus on happy-path validation of business flows
E2E tests can fail for reasons unrelated to the coding issues. Capture the frequency and cause of failures so that efforts can be made to make them more stable.
Vertical E2E tests should be maintained by the team at the start of the flow and versioned with the component (UI or service).
CD pipelines should be optimized for the rapid recovery of production issues. Therefore, horizontal E2E tests should not be used to block delivery due to their size and relative failure surface area.
A team may choose to run vertical E2E in their pipeline to block delivery, but efforts must be made to decrease false positives to make this valuable.
Alternate Terms
Integration test and end to end are often used internchangeably.
Customer Experience Alarms are a type of active alarm. It is a piece of software that sends requests to your system much like a user would. We use it to test the happy-path of critical customer workflows. These requests happen every minute (ideally, but can be as long as every 5 minutes). If they fail to work, or fail to run, we emit metrics that cause alerts. We run these in all of our environments, not just production, to ensure that they work and we catch errors early.
These are different than having log-based alarms because we can’t guarantee that someone is working through all of the golden-path workflows for our system at all times. If we rely entirely on logs, we wouldn’t know if the golden workflows are accurate when we deploy at 3am on a Saturday due to an automated process.
These tests have a few important characteristics:
They are run in all environments, including production.
They aren’t generated from UI workflows, but rather from direct API access
They ideally run every minute.
If they don’t work (in production) they page someone. Even at 3am.
Alternate Terms
Synthetic Probes (Google)
Canary (Amazon, although it doesn’t mean what Canary means here)
5.6 - Functional Testing
A functional test is a deterministic test that verifies that all modules of a sub-system are working together. They should avoid integrating with other sub-systems as this tends to reduce determinism. Instead, test doubles are preferred. Examples could include testing the behavior of a user interface through the UI or testing the business logic of individual services through the API.
At a high level functional testing is a means of verifying a systems specification and fundamental requirements in a systematic and deterministic way. Functional tests further unit and integration tests by introducing an actor, typically a user or service consumer, and validating the ingress and egress of that actor. Functional tests allow for capturing, within specific consumer environments, potential issues that are inherit to that context. More often than not a functional test will cover broad-spectrum behavioral tests such as UI interactions, presentation-logic, and business-logic and their respective side-effects; Side-effects at this level are mocked and do not cross or proxy to boundaries outside of the systems control – contrast that to E2E tests where there are no mocks.
Recommended Best Practices
Tests should be written from the lens of an “actor” be that a user interacting with a UI component or a service interacting with a potentially stateful API.
Proxying or otherwise real I/O should be avoided to reduce flakiness and ensure deterministic side-effects.
Test doubles should generally always be used in the case where the system under test needs to interact with an out-of-context sub-system.
Framework: jest Assertion & Mocking: expect (jest) - generic, supertest or nock - http server endpoint, apollo - graphql server testing Code Coverage: instanbul/nyc (jest)
5.7 - Integration Testing
An integration test is a deterministic test to verify how the unit under test interacts with other units without directly accessing external sub-systems. For the purposes of clarity, “integration test” is not a test that broadly integrates multiple sub-systems. That is an E2E test.
Some examples of an integration test are validating how multiple units work together (sometimes called a “sociable unit test”) or validating the portion of the code that interfaces to an external network sub-system while using a test double to represent that sub-system.
Validating the behavior of multiple units with no external sub-systems
Validating the portion of the code that interfaces to an external network
sub-system
When designing network integration tests, it’s recommended to also have contract tests running asynchronously to validate the service test doubles.
Recommended Best Practices
Integration tests provide the best balance of speed, confidence, and cost when building tests to ensure your system is properly functioning. The goal of testing is to give developers confidence when refactoring, adding features or fixing bugs. Integration tests that are decoupled from the implementation details will give you this confidence without giving you extra work when you refactor things. Too many unit tests, however, will lead to very brittle tests. If you refactor code (i.e. change the implementation w/out changing the functionality) the goal should be to NOT break any tests and ideally not even touch them at all. If lots of tests are breaking when you refactor, it’s probably a sign of too many unit tests and not enough integration tests.
Tests should be written from the perspective of how the actor experiences it.
Avoid hasty abstractions. Duplication in tests is not the enemy. In fact, it’s often better to have duplicated code in tests than it is to have complex abstractions. Tests should be damp, not DRY.
Design tests that alert to failure as close to defect creation as possible.
“Don’t poke too many holes in reality.” Only use mocks or test doubles when absolutely necessary to maintain determinism in your test. Justin Searls has a great talk about this.
Flakey tests need to be corrected to prevent false positives that degrade the ability of the tests to act as an effective code gate.
Write tests from the actor’s perspective and don’t introduce a test user. (e.g. When I give this input, I expect this outcome)
End-User - when building a UI, what response will each input provide to the user?
Consumer - when building a library or service, what output will be expected for a given input?
Don’t test implementation details. Tests should focus on what the outcomes are, not how the outcomes occurred.
Examples of testing implementation details include:
internal state
private methods/properties etc
things a user won’t see/know about.
Integration tests are normally run with unit tests.
Service Integration Tests
Service integration tests are focused on validating how the system under test responds to information from an external service and that service contracts can be consumed as expected. They should be deterministic and should not test the behavior of the external service. The integration can be from UI to service or service to service. A typical service integration test is a set of unit tests focused on interface schema and response codes for the expected interaction scenarios.
Use virtual services or static mocks instead of live services to ensure the test is repeatable and deterministic.
Implement contract tests to continuously validate the virtual service or mock is current.
Don’t over-test. When validating service interactions, testing that a dependency returns a specific value is testing the behavior of the dependency instead of the behavior of the SUT.
Database Integration Tests
Test data management is one of the more complex problems, so whenever possible using live data should be avoided.
Good practices include:
In-memory databases
Personalized datasets
Isolated DB instances
Mocked data transfer objects
Front End Driven Integration Tests
Don’t use tools like Enzyme that let you peek behind the curtain.
Follow the Accessibility order of operations to get a reference to elements (in prioritized order):
Things accessible to all users (Text, placeholder, label, etc)
Accessibility features (role, title, alt tag, etc)
Only after exhausting the first 2, then use test ID or CSS/XPath selectors as an escape hatch. But remember, the user doesn’t know about these so try to avoid them.
Alternate Terms
Sociable Unit Test
Alternate Definitions
When integrating multiple sub-systems into a larger system: this is an End to End Test.
When testing all modules within a sub-system through the API or user interface: this is a Functional Test.
describe("retrieving Hygieia data",()=>{it("should return counts of merged pull requests per day",async()=>{constsuccessStatus=200;constresult=awaithygieiaConnector.getResultsByDay(hygieiaConnector.hygieiaConfigs.integrationFrequencyRoute,testConfig.HYGIEIA_TEAMS[0],testConfig.getTestStartDate(),testConfig.getTestEndDate());expect(result.status).to.equal(successStatus);expect(result.data).to.be.an("array");expect(result.data[0]).to.haveOwnProperty("value");expect(result.data[0]).to.haveOwnProperty("dateStr");expect(result.data[0]).to.haveOwnProperty("dateTime");expect(result.team).to.be.an("object");expect(result.team).to.haveOwnProperty("totalAllocation");});it("should return an empty array if the team does not exist",async()=>{constresult=awaithygieiaConnector.getResultsByDay(hygieiaConnector.hygieiaConfigs.integrationFrequencyRoute,0,testConfig.getTestStartDate(),testConfig.getTestEndDate());expect(result.status).to.equal(successStatus);expect(result.data).to.be.an("array");expect(result.data.length).to.equal(0);});});
Recommended Tooling
Integration Tooling is the same as recommended for Unit Tests
5.8 - Static Testing
A static test is a test that evaluates non-running code against rules for known good practices to check for security, structure, or practice issues.
It warns of excessive complexity in the code that will degrade the ability to change it safely.
Identifies issues that could expose vulnerabilities
Shows anti-patterns that violate good practices
Alerts to issues with dependencies that may prevent delivery, create a vulnerability, or even expose the company to lawsuits.
It catches errors
Principles
When implementing any test, the test should be designed to provide alerts as close to the moment of creation as possible.
Static analysis, many scans can be run realtime in IDEs. Others during the build or as a pre-commit scan. Others require tooling that can only be used on the CI server. Whatever the test, drive it left.
Recheck everything on CI while verifying HEAD
Types of static tests
Linting: This automates catching of common errors in code and the enforcement of best practices
Formatting: Enforcement of code style rules. It removes subjectivity from code reviews
Complexity: Are code blocks too deep or too long? Complexity causes defects and simple code is better.
Type checking: Type checking can be a key validation to prevent hard to identify defects replacing certain classes of tests and logic otherwise required (e.g. unit tests validating internal APIs)
Security: Checking for known vulnerabilities and coding patterns that provide attack vectors are critical
Dependency scanning :
Are your dependencies up to date?
Has the dependency been hijacked?
Are there known security issues in this version that require immediate resolution?
Is it licensed appropriately?
Recommended Best Practices
IDE plugins to identify problems in realtime
Pre-commit hooks to prevent committing problems
Verification during PR and during the CI build on the HEAD to verify that earlier verification happened and was effective.
Discourage disabling of static tests (e.g. skipping tests, ignoring warnings, ignoring code on coverage evaluation, etc)
Write custom rules (lint, formatting, etc) for common code review feedback
Test doubles are one of the main concepts we use to create fast, independent, deterministic and reliable tests. Similar to the way Hollywood uses a _stunt double* to film dangerous scenes in a movie to avoid the costly risk a high paid actor gets hurt, we use a test double in early test stages to avoid the speed and dollar cost of using the piece of software the test double is standing in for. We also use test doubles to force certain conditions or states of the application we want to test. Test doubles can be used in any stage of testing but in general, they are heavily used during the initial testing stages in our CD pipeline and used much less in the later stages. There are many different kinds of test doubles such as stubs, mocks, spies, etc.
Test Double: A test double is a generic term for any case where you replace a production object for testing purposes.
Dummy: A dummy is passed around but never actually used. Usually it is just used to fill parameter lists.
Fake: A fake actually has a working implementation, but usually takes some shortcut which makes it not suitable for production (an InMemoryTestDatabase is a good example).
Stub: A stub provides canned answers to calls made during the test, usually not responding at all to anything outside what’s programmed in for the test.
Spy: A spy is a stub that also records some information based on how it was called. One form of this might be an email service that records how many messages it was sent.
Mock: A mock is pre-programmed with expectations which form a specification of the calls it is expected to receive. It can throw an exception if it receives a call it doesn’t expect and is checked during verification to ensure it got all the calls it was expecting.
@Beforepublicvoidinit()throwsException{// ===============Arrange===============userService=Mockito.spy(userService);ObjectMappermapper=newObjectMapper();// Here we are putting data from user_spy.jsonspyData=mapper.readValue(newFile(TestConstants.DATA_FILE_ROOT+"user_spy.json"),User.class);Mockito.doReturn(spyData).when(userService).getUserInfo(TestConstants.userId);// spy json data for the user data}@Test// Mock the userServicepublicvoidverifySpyUserDetails()throwsException{// ===============Act===============Useruser=userService.getUserInfo(TestConstants.userId);// user data comes from spyverify(userService).getUserInfo(TestConstants.userId);// verify the userservice.getUserInfo method is calledverify(userService,times(1)).getUserInfo(TestConstants.userId);// verify from spy the getUserInfo called one// ===============Assert===============// validate the expected spyData is matching with actual user DataAssert.assertEquals(spyData.getManager(),user.getManager());Assert.assertEquals(spyData.getVp(),user.getVp());Assert.assertEquals(spyData.getOrganization(),user.getOrganization());Assert.assertEquals(spyData.getDirector(),user.getDirector());Assert.assertEquals(spyData.getDirector(),user.getDirector());}@AfterpublicvoidcleanUp(){reset(userService);// Reseting the userServiceSpy}
Simplistic but powerful api that can support state
Easy to use. Start MWS before test, initialize netApi with the baseUrl of the MWS instance, configure in test’s // GIVEN phase, stop server after.
iOS
For iOS, Apple test frameworks support a rich feature set, documentation and community. As a team we prefer using 1P tooling and adding Homegrown solution on top of it. The reason we do this is because Apple has been notorious in changing API’s at rapid iterations. This also results us to constantly update 3P solutions which have a risk of getting discontinued and maintaining them is a challenge. Hence iOS team prefers to use more maintainable solution which would be 1P with additional Homegrown Utilities as required.
Has annotations for easy creation of many mocks at test construction
5.10 - Unit Testing
Unit tests are deterministic tests that exercise a discrete unit of the application, such as a function, method, or UI component, in isolation to determine whether it behaves as expected.
When testing the specs of functions, prefer testing public API (methods, interfaces, functions) to private API: the spec of private functions and methods are meant to change easily in the future, and unit-testing them would amount to writing a Change Detector Test, which is an anti-pattern.
The purpose of unit tests are to:
Verify the functionality of a unit (method, class, function, etc.) in isolation
Good for testing hi-complexity logic where there may be many permutations (e.g. business logic)
Keep Cyclomatic Complexity low through good separations of concerns and architecture
Principles
Unit tests are low-level and focus on discrete units of the application
All dependencies are typically replaced with test-doubles to remove non-determinism
Unit tests are fast to execute
Test Suite is ran after every code change
Recommended Best Practices
Run a subset of your test suite based on the part of the code your are currently working on
Following TDD practices plus the watch functionality of certain testing frameworks is an easy way to achieve this
Pre-commit hooks to run the test suite before committing code to version control
Verification during PR and during the CI build on the HEAD to verify that earlier verification happened and was effective.
Discourage disabling of static tests (e.g. skipping tests, ignoring warnings, ignoring code on coverage evaluation, etc)
Write custom rules (lint, formatting, etc) for common code review feedback
// Example from lodash
describe('castArray',()=>{it('should wrap non-array items in an array',()=>{constvalues=falsey.concat(true,1,'a',{a:1});constexpected=lodashStable.map(values,(value)=>[value]);constactual=lodashStable.map(values,castArray);expect(actual).toEqual(expected);});it('should return array values by reference',()=>{constarray=[1];expect(castArray(array)).toBe(array);});it('should return an empty array when no arguments are given',()=>{expect(castArray()).toEqual([]);});});
@Test// Mock the userServicepublicvoidverifyMockedUserDetails()throwsException{// ===============Arrange===============ObjectMappermapper=newObjectMapper();UseruserMockData=mapper.readValue(newFile(TestConstants.DATA_FILE_ROOT+"user_mock.json"),User.class);// This code mocks the getUserInfo method for userService// Any call made to the getUserInfo will not make actual method call instead// returns the userMockDataMockito.when(userService.getUserInfo(TestConstants.userId)).thenReturn(userMockData);// ===============Act===============RequestBuilderrequestBuilder=MockMvcRequestBuilders.get("/user/"+TestConstants.userId).accept(MediaType.APPLICATION_JSON);MvcResultmvcResponse=mockMvc.perform(requestBuilder).andReturn();StringresponsePayload=mvcResponse.getResponse().getContentAsString();Stringstatus=JsonPath.parse(responsePayload).read("$.STATUS");Map<String,String>userMap=JsonPath.parse(responsePayload).read("$.payload");// ===============Assert===============JSONAssert.assertEquals(TestConstants.PARTIAL_MOCK_SUCCESS_PAYLOAD,responsePayload,false);// disable strict// validate the expected userMockData is matching with actual userMap DataAssert.assertEquals(TestConstants.SUCCESS,status);Assert.assertEquals(userMockData.getManager(),userMap.get("manager"));Assert.assertEquals(userMockData.getVp(),userMap.get("vp"));Assert.assertEquals(userMockData.getOrganization(),userMap.get("organization"));Assert.assertEquals(userMockData.getDirector(),userMap.get("director"));Assert.assertEquals(userMockData.getCostcenter(),userMap.get("costcenter"));}
Recommended Tooling
Platform
Tools
Android
Framework: JUnit5 Assertion: Google Truth
iOS
XCTest
Web
Framework: jest Assertion & Mocking: expect (jest), jest-dom, others as necessary Code Coverage: instanbul/nyc (jest)
Framework: jest Assertion & Mocking: expect (jest) - generic, supertest or nock - http server endpoint, apollo - graphql server testing Code Coverage: instanbul/nyc (jest)
6 - Work Decomposition
Tips for breaking down work to “small enough”.
Reducing the batch size of delivered work is one of the most important things we can do to drive improved workflow,
quality, and outcomes. Why?
We have fewer assumptions in the acceptance criteria because we had to define how to test them. The act of defining them as tests brings out questions. “How can we validate that?”
We are less subject to hope creep. We can tell within a day that we bit off more than we thought and can communicate that.
When we deliver and discover the story was wrong, we’ve invested less in money, time, and emotional attachment so we can easily pivot.
It makes us predictable
It helps to reset our brains on what “small” is. What many people consider small turns out to be massive once they see what small really is.
The following playbooks have proven useful in helping teams achieve this outcome.
6.1 - From Roadmap to User Story
Aligning priorities across multi-team products can be challenging. However, the process used at the team level to decompose work
functions just as well at the program level.
Program Roadmap
In order to have an effective work breakdown process, goals and priorities need
to be established and understood.
Stakeholders and leadership teams must define the high-level initiatives, and
their priorities, so that work may be dispersed among product teams.
Leadership teams can be made up of a core group of product owners.
Product Roadmap
The program roadmap should breakdown into the product roadmap, which includes
the prioritized list of epics for each product.
The leadership team should define the product vision, roadmap, and dependencies
for each product.
Team Backlog
The team backlog should be comprised of the prioritized epics from the product roadmap.
The core group needed to effectively break down high level requirements so that
the team may decompose work includes product owners,
tech leads, and project managers.
Product teams should use the processes effective for
Work Decomposition, to breakdown
epics into smaller epics, stories, and tasks.
6.2 - Work Decomposition
In order to effectively understand and implement the work breakdown flow, the
team needs to have the following prerequisites and understandings.
Backlog refinement cadence with the appropriate team members and stakeholders involved
Work Breakdown Process
The goal of the work breakdown process is to decompose work into small batches
that can be delivered frequently, multiple times a week, to deliver value faster with less rework.
The general work breakdown process involves:
It is important that the team keep these tips in mind when decomposing work:
Known poor quality should not flow downstream. This includes acceptance criteria that require interpretation. If the
acceptance criteria cannot be understood by the whole team then we are developing defects, not value.
Refining work requires significant brainpower and is the primary quality process. Meetings should be planned around
this. Hold them when people are mentally alert and time box them to prevent mental fatigue.
Good acceptance criteria come from good communication. Avoid the following anti-patterns:
Someone outside the team writes acceptance criteria and hands it to the team. Since the team was not involved with
the conversation, there’s no chance to uncover assumptions and the team has less investment in the outcomes.
One person on the team writes acceptance criteria. The same problem is above.
Each team member is assigned work based on their expertise. This removes communication and also ensures that
people are only focused on understanding their tasks. Again, the team as a whole isn’t invested in the
outcomes. This typically results in finger-pointing when something fails. Also, if someone is unavailable, the
rest of the team lacks context to pick it up.
Refining should be focused on outcomes, not volume. If we have a 1-hour meeting and 10 stories to refine, it’s better
to have one fully refined story we can work on than 10 partially refined stories that we’ll “figure out during
development”. Stop refining a story when we agree on the acceptance criteria or agree it’s blocked and needs more
information. Only then should we move to the next story. Stop the meeting at the scheduled time.
Intake/Product Ideas
Ideas become epics with defined outcomes, clear goals and value.
Epics become a list of features.
Common struggles for teams when breaking down ideas into epics and features:
Stories are observable changes that have clear acceptance criteria and can be
completed in less than two days. Stories are made up of one or more tasks.
Typical problems teams experience with decomposition are:
Tasks are independently deployable changes that can be merged to trunk daily.
Breaking stories down into tasks gives teams the ability to swarm work and deliver value faster.
For teams to visualize tasks required to implement scenarios, they need to understand what a good task looks like.
Measuring Success
Tracking the team’s Development Cycle Time is the best way to judge improvements
to decomposition. Stories should take 1-2 days to deliver and should not have rework, delays waiting for
explanations, or dependencies on other stories or teams.
6.3 - Behavior Driven Development
Behavior Driven Development is the collaborative process where we discuss the intent and behaviors of a feature and
document the understanding in a declarative, testable way. These testable acceptance criteria should be the
Definition of Done for a
user story.
BDD is not a technology or automated tool. BDD is the process of defining the behavior. We can then
automate tests for those behaviors.
Example:
Feature: I need to smite a rabbit so that I can find the Holy Grail
Scenario: Use the Holy Hand Grenade of Antioch
Given I have the Holy Hand Grenade of Antioch
When I pull the pin
And I count to 3But I do not count to 5And I lob it towards my foe
And the foe is naughty in my sight
Then my foe should snuff it
Recommended Practices
Gherkin is the domain specific
language that allows acceptance criteria to be expressed in “Arrange, Act, Assert” in a
way that is understandable to all stakeholders.
Example:
Feature: As an hourly associate I want to be able to log my arrival time so that I can be
paid correctly.
Scenario: Clocking in
Given I am not clocked in
When I enter my associate number
Then my arrival time will be logged
And I will be notified of the time
Scenario: Clocking out
Given I am clocked in
When I enter my associate number
And I have been clocked in for more than 5 minutes
Then I will be clocked out
And I will be notified of the time
Scenario: Clocking out too little time
Given I am clocked in
When I enter my associate number
And I have been clocked in for less than 5 minutes
Then I will receive an error
Using Acceptance Criteria to Negotiate and Split
With the above criteria, it may be acceptable to remove the time validation and accelerate the delivery of the time
logging ability. After delivery, we may learn that the range validation
isn’t required. If true, we’ve saved money and time by NOT delivering
unneeded features.
First, we deliver the ability to clock in and see if we really do need the ability
to verify.
Feature: As an hourly associate I want to be able to log my arrival time so that I can be
paid correctly.
Scenario: Clocking in
Given I am not clocked in
When I enter my associate number
Then my arrival time will be logged
And I will be notified of the time
Scenario: Clocking out
Given I am clocked in
When I enter my associate number
And I have been clocked in for more than 5 minutes
Then I will be clocked out
And I will be notified of the time
If, in production, we discover that the sanity check is required to prevent time
clock issues, we can quickly add that behavior.
Feature: As an hourly associate I want to be prevented from clocking out immediately after
clocking in.
Scenario: Clocking out more than 5 minutes after arrival
Given I am clocked in
And I have been clocked in for more than 5 minutes
When I enter my associate number
Then I will be clocked out
And I will be notified of the time
Scenario: Clocking out less than 5 minutes after arrival
Given I am clocked in
And I have been clocked in for less than 5 minutes
When I enter my associate number
Then I will receive an error
Tips
Scenarios should be written from the point of view of the consumer. If the consumer; either a user, UI, or another service.
Scenarios should be focused on a specific function and should not attempt to
describe multiple behaviors.
If a story has more than 6 acceptance criteria, it can probably be split.
No acceptance test should contain more than 10 conditions. In fact, much less
is recommended.
Acceptance tests can be used to describe a full end-to-end user experience. They are also recommended for describing
the behavior of a single component in the flow of the overall behavior.
A development task is the smallest independently deployable change to implement
acceptance criteria.
Recommended Practices
Create tasks that are meaningful and take less than two days to complete.
Given I have data available for Integration Frequency
Then score entry for Integration Frequency will be updated for teams
Task: Create Integration Frequency Feature Flag.
Task: Add Integration Frequency as Score Entry.
Task: Update Score Entry for Integration Frequency.
Use Definition of Done as your
checklist for completing a development task.
Tips
If a task includes integration to another dependency, add a simple contract
mock to the task so that parallel development of the consumer and provider will
result in minimal integration issues.
Decomposing stories into tasks allows teams to swarm stories and deliver value
faster
6.5 - Contract Driven Development
Contract Driven Development is the process of defining the contract changes
between two dependencies during design and prior to construction. This allows
the provider and consumer to work out how components should interact so that
mocks and fakes can be created that allow the components to be developed and
delivered asynchronously.
Recommended Practices
For services, define the expected behavior changes for the affected verbs along
with the payload. These should be expressed as contract tests, the unit test of
an API, that both provider and consumer can use to validate the integration independently.
For more complicated interaction that require something more than simple canned
responses, a common repository that represents a fake of the new service or tools
like Mountebank or WireMock
can be used to virtualize more complex behavior. It’s important that both
components are testing the same behaviors.
Contract tests should follow Postel’s Law:
"Be conservative in what you do, be liberal in what you accept from others".
Tips
For internal services, define the payload and responses in the developer task
along with the expected functional test for that change.
For external services, use one of the open source tools that allow recording
and replaying responses.
Always create contract tests before implementation of behavior.
6.6 - Defining Product Goals
Product Goals
Product goals are a way to turn your vision for your product into easy to
understand objectives that can be measured and achieved in a certain amount of time.
Increased transparency into product metrics
Measurable Outcome: Increased traffic to product page
When generating product goals, you need to understand what problem you are
solving, who you are solving it for, and how you measure that you achieved the goals.
Initiatives
Product goals can be broken down into initiatives, that when accomplished,
deliver against the product strategy.
Provide one view for all product KPIs.
Ensure products have appropriate metrics associated with them.
Initiatives can then be broken down into epics, stories, tasks, etc. among
product teams, with high-level requirements associated.
Epics
An epic is a complete business feature with outcomes defined before
stories are written. Epics should never be open ended buckets of work.
I want to be able to review the CI metrics trends of teams who have completed a
DevOps Dojo engagement.
Tips
Product goals need a description and key results needed to achieve
them.
Initiatives need enough information to help the team understand the expected
value, the requirements, measure of success, and the time frame associated to completion.
6.7 - Definition of Ready
Is it REALLY Ready?
A Definition of Ready is a set of criteria decided by the team that defines when
work is ready to begin. The goal of the Definition of Ready to help the team
decide on the level of uncertainty that they are comfortable with taking on with
respect to their work. Without that guidance, any work is fair game. That is a
recipe for confusion and disaster.
Recommended Practices
When deciding on a Definition of Ready, there are certain minimum criteria that
should always be there. These are:
Description of the value the work provides (Why do we want to do this?)
Testable Acceptance Criteria (When do we know we’ve done what we need to?)
The team has reviewed and agreed the work is ready (Has the team seen it?)
However, the context of a team can make many other criteria applicable. Other
criteria could include:
Wireframes for new UI components
Contracts for APIs/services we depend on
All relevant test types identified for subtasks
Team estimate of the size of the story is no more than 2 days
The Definition of Ready is a living document that should evolve over time as
the team works to make their delivery system more predictable. The most
important thing is to actually enforce the Definition of Ready. If it’s not
enforced, it’s completely useless.
If any work in “Ready to Start” does not meet the Definition of Ready, move
it back to the Backlog until it is refined.
Any work that is planned for a sprint/iteration must meet the Definition of
Ready. Do not accept work that isn’t ready!
If work needs to be expedited, it needs to go through the same process.
(Unless there is immediate production impact, of course)
Definition of Ready is also useful for support tickets or other types of work
that the team can be responsible for. It’s not just for development work!
It’s up to everyone on the team, including the Product Owner, to make sure
that non-ready work is refined appropriately.
The recommended DoR for CD is that any story can be completed, either by the team or a single developer, in 2 days or less
6.8 - Spikes
Spikes are an exploration of potential solutions for work or research items that cannot be estimated. They
should be time-boxed in short increments (1-3 days).
Recommended Practices
Since all work has some amount of uncertainty and risk, spikes should be used
infrequently when the team has no idea on how to proceed with a work item. They
should result in information that can be used to better refine work into something
valuable, for some iteration in the future.
Spikes should follow a Definition of Done,
with acceptance criteria, that can be demoed at the end of its timebox.
A spike should have a definite timebox with frequent feedback to the team on what’s been learned so far. It can be
tempting to learn everything about the problem and all of the solutions before trying anything, but the best way to
learn is to learn using the problem in front of us right now. Batching learning is worse than batching other kinds of
work because effective learning requires applying the learning immediately or it’s lost.
Tips
Use spikes sparingly, only when high uncertainty exists.
Spikes should be focused on discovery and experimentation.
Stay within the parameters of the spike. Anything else is considered a waste.
6.9 - Story Slicing
Story slicing is the activity of taking large stories and splitting them into
smaller, more predictable deliveries. This allows the team to deliver higher
priority changes more rapidly instead of tying those changes to others that may
be of lower relative value.
Recommended Practices
Stories should be sliced vertically.
That is, the story should be aligned such that it fulfills a consumer request
without requiring another story being deployed. After slicing, they should still
meet the INVEST principle.
Example stories:
As an hourly associate I want to be able to log my arrival time so that I can be
paid correctly.
As a consumer of item data, I want to retrieve item information by color so that
I can find all red items.
Stories should not be sliced along tech stack layer or by activity. If you
need to deploy a UI story and a service story to implement a new behavior, you
have sliced horizontally.
Do not slice by tech stack layer
UI “story”
Service “story”
Database “story”
Do not slice by activity
Coding “story”
Review “story”
Testing “story”
Tips
If you’re unsure if a story can be sliced thinner, look at the acceptance
tests from the BDD activity and see if it
makes sense to defer some of the tests to a later release.
While stories should be sliced vertically, it’s quite possible that multiple
developers can work the story with each developer picking up a task that
represents a layer of the slice.
Minimize hard dependencies in a story. The odds of delivering on time for any
activity are 1 in 2^n where n is the number of hard dependencies.
7 - 24 Capabilities to Drive Improvement
“Our research has uncovered 24 key capabilities that drive improvements in software delivery performance in a statistically significant way. Our book details these findings.”
Version control is the use of a version control system, such as GitHub or Subversion, for all production artifacts,
including application code, application configurations, system configurations, and scripts for automating build and
configuration of the environment.
Automate your deployment process
Deployment automation is the degree to which deployments are fully automated and do not require manual intervention.
Implement continuous integration
Continuous integration (CI) is the first step towards continuous delivery.
This is a development practice where code is regularly
checked in, and each check-in triggers a set of quick tests to discover serious regressions, which developers fix immediately. The
CI process creates canonical builds and packages that are ultimately deployed and released.
Use trunk-based development methods
Trunk-based development has been shown to be a predictor of high performance in software development and delivery. It is
characterized by fewer than three active branches in a code repository; branches and forks having very short lifetimes
(e.g., less than a day) before being merged into trunk; and application teams rarely or never having code lock periods
when no one can check in code or do pull requests due to merging conflicts, code freezes, or stabilization phases.
Implement test automation
Test automation is a practice where software tests are run automatically (not manually) continuously throughout the
development process. Effective test suites are reliable—that is, tests find real failures and only pass releasable code.
Note that developers should be primarily responsible for creation and maintenance of automated test suites.
Support test data management
Test data requires careful maintenance, and test data management is becoming an increasingly important part of automated
testing. Effective practices include having adequate data to run your test suite, the ability to acquire necessary data
on demand, the ability to condition your test data in your pipeline, and the data not limiting the amount of tests you
can run. We do caution, however, that teams should minimize, whenever possible, the amount of test data needed to run
automated tests.
Shift left on security
Integrating security into the design and testing phases of the software development process is key to driving IT
performance. This includes conducting security reviews of applications, including the Infosec team in the design and
demo process for applications, using pre-approved security libraries and packages, and testing security features as a
part of the automated testing suite.
Implement continuous delivery (CD)
CD is a development practice where software is in a deployable state throughout its lifecycle, and the team prioritizes keeping the
software in a deployable state over working on new features. Fast feedback on the quality and deployability of the system is
available to all team members, and when they get reports that the system isn’t deployable, fixes are made quickly.
Finally, the system can be deployed to production or end users at any time, on demand.
Architecture Capabilities
Use a loosely coupled architecture
This affects the extent to which a team can test and deploy their applications on demand, without requiring orchestration with other
services. Having a loosely coupled architecture allows your teams to work independently, without relying on other teams for support
and services, which in turn enables them to work quickly and deliver value to the organization.
Architect for empowered teams
Our research shows that teams that can choose which tools to use do better at continuous delivery and, in turn, drive
better software development and delivery performance. No one knows better than practitioners what they need to be
effective.
Product and Process Capabilities
Gather and implement customer feedback
Our research has found that whether organizations actively and regularly seek customer feedback and incorporate this
feedback into the design of their products is important to software delivery performance.
Make the flow of work visible through the value stream
Teams should have a good understanding of and visibility into the flow of work from the business all the way through to
customers, including the status of products and features. Our research has found this has a positive impact on IT
performance.
Work in small batches
Teams should slice work into small pieces that can be completed in a week or less. The key is to have work decomposed
into small features that allow for rapid development, instead of developing complex features on branches and releasing
them infrequently. This idea can be applied at the feature and the product level. (An MVP is a prototype of a product
with just enough features to enable validated learning about the product and its business model.) Working in small
batches enables short lead times and faster feedback loops.
Foster and enable team experimentation
Team experimentation is the ability of developers to try out new ideas and create and update specifications during the
development process, without requiring approval from outside of the team, which allows them to innovate quickly and
create value. This is particularly impactful when combined with working in small batches, incorporating customer
feedback, and making the flow of work visible.
Lean Management and Monitoring Capabilities
Have a lightweight change approval process
Our research shows that a lightweight change approval process based on peer review (pair programming or intra-team code
review) produces superior IT performance than using external change approval boards (CABs).
Monitor across application and infrastructure to inform business decisions
Use data from application and infrastructure monitoring tools to take action and make business decisions. This goes
beyond paging people when things go wrong.
Check system health proactively
Monitor system health, using threshold and rate-of-change warnings, to enable teams to preemptively detect and mitigate problems.
Improve processes and manage work with work-in-progress (WIP) limits
The use of work-in-progress limits to manage the flow of work is well known in the Lean community. When used
effectively, this drives process improvement, increases throughput, and makes constraints visible in the system.
Visualize work to monitor quality and communicate throughout the team
Visual displays, such as dashboards or internal websites, used to monitor quality and work in progress have been shown
to contribute to software delivery performance.
Cultural Capabilities
Support a generative culture (as outlined by Westrum)
This measure of organizational culture is based on a typology developed by Ron Westrum, a sociologist who studied
safety-critical complex systems in the domains of aviation and healthcare. Our research has found that this measure of
culture is predictive of IT performance, organizational performance, and decreasing burnout. Hallmarks of this measure
include good information flow, high cooperation and trust, bridging between teams, and conscious inquiry.
Encourage and support learning
Is learning, in your culture, considered essential for continued progress? Is learning thought of as a cost or an
investment? This is a measure of an organization’s learning culture.
Support and facilitate collaboration among teams
This reflects how well teams, which have traditionally been siloed, interact in development, operations, and information security.
Provide resources and tools that make work meaningful
This particular measure of job satisfaction is about doing work that is challenging and meaningful, and being empowered
to exercise your skills and judgment. It is also about being given the tools and resources needed to do your job well.
Support or embody transformational leadership
Transformational leadership supports and amplifies the technical and process work that is so essential in DevOps. It is
comprised of five factors: vision, intellectual stimulation, inspirational communication, supportive leadership, and
personal recognition.
8 - Value Stream Mapping
The purpose of the Value Stream Mapping Workshop is to uncover all of the steps required to take an idea from conception to production. The goal is to uncover the following:
Steps that exist that can be removed
Steps that require waiting on another step to continue the flow
Steps that have a high defect rate
We use the outcome to design an improved value stream so we can prioritize the changes required to reduce the waste in the current flow.
Prerequisites
For a “to be” value stream, there must be an established process for value delivery.
Everyone who has a touch point in the value stream should be present for the exercise. This includes, but is not
limited to developers, managers, product owners, and representatives from external teams that have required steps
between conception and production.
Understand terms associated with value stream mapping.
Wait time/non-value time: Time between processes where activity is not occurring.
Process time/value add time: Time spent executing a step in the value stream.
Percent Complete/Accurate: Percentage of work that is not rejected by the next step in the process. i.e. If code fails
code review 20% of the time, the %C/A is 80%.
Recommended Practices
When value stream mapping your team, start from delivery and move backward through each step. You are less likely to miss steps in the process.
Identify the source
Example Team Demo
For each source of Requests
What is the average process time for this step?
Who is involved in this step?
What percentage of work is rejected by the next step in the process?
Your team will need to identify these things for each step in the process. Don’t forget to identify where your intake process originated, whether that be stakeholder conversations, service desk, etc.
Identify Rework Loops
After your team has completed the initial value stream map, they have most likely identified a few rework loops. Rework
loops are interruptions in the value stream where steps have to be corrected.
In this example, the team had to fix code review comments 10% of the time before they could be reviewed and merged into master.
Identify Wait Time
Once your team has completed the above steps, you will go back through the value stream to identify the wait time
between each step in the process. Make sure to take your cadence into account when calculating.
Add your total process time/wait time to get an average lead time. Understand that the value stream is an
estimate/average based on your team’s feedback.
Outcomes
Process time/wait time of your flow.
Visual representation of the value stream(s) of the team.
Possible constraints to your flow based on process time/wait time, rework loops, and percent complete/accurate. You
can present these on your VSM as kaizen bursts.
Tips
Review and maintain the value stream map to show wins associated with your team’s improvement plan.
Take into account all potential flows for team processes, and value stream those as well.
Value
As a team, we want to understand how to value stream map our team processes, so that we may understand our constraints
to delivery and identify ways to improve.
Acceptance Criteria
Value stream all things associated with delivering value.