The ability to deliver the latest changes to production on demand.
Continuous Deployment
Delivering the latest changes to production as they occur.
Continuous Integration
Continuous integration requires that every time somebody commits any change, the entire application is built and a comprehensive
set of automated tests is run against it. Crucially, if the build or test process fails, the development team stops whatever they
are doing and fixes the problem immediately. The goal of continuous integration is that the software is in a working state all the
time.
Continuous integration is a practice, not a tool. It requires a degree of commitment and discipline from your development team.
You need everyone to check in small incremental changes frequently to mainline and agree that the highest priority task on the
project is to fix any change that breaks the application. If people don’t adopt the discipline necessary for it to work, your
attempts at continuous integration will not lead to the improvement in quality that you hope for.
– “Continuous Delivery: Reliable Software Releases through Build, Test, and Deployment
Automation.” - Jez Humble & David Farley
A hard dependency is something that must be in place before a feature is
delivered. In most cases, a hard dependency can be converted to a soft dependency with feature flags.
Soft Dependency
A soft dependency is something that must be in place before a feature can be fully functional, but does not block the
delivery of code.
Story Points
A measure of the relative complexity of delivering a story. Historically, 1 story point was 1 “ideal
day”. An ideal day is a day where there are no distractions, the code is flowing, and we aren’t waiting on anything. No
such day exists. :wink:
There are many common story point dysfunctions: pointing defects, unplanned work, and spikes are some of the more
common. Adjusting points after work is done is another common mistake. The need for story points is a good indication
that we do not understand the work. If we have decomposed the work correctly, everything should be 1 point.
Toil
The repetitive, predictable, constant stream of tasks related to
maintaining an application.
Any work that the team inserts before the current planned work. Critical defects and “walk up” requests are unplanned
work. It’s important that the team track all unplanned work and the reason so that steps can be taken by the team to
reduce the future impact.
Vertical Sliced Story
A story should represent a response to a request that can be deployed
independently of other stories. It should be aligned across the tech stack so
that no other story needs to be deployed in concert to make the function work.
Examples:
Submitting a search term and returning results.
Requesting user information from a service and receiving a response.
WIP
Work in progress is any work that has been started but not delivered to the end-user
2 - Value Stream Mapping
A guide to conducting a Value Stream Mapping Workshop to optimize your development process.
The Value Stream Mapping Workshop uncovers all steps from idea conception to production, aiming to identify removable steps, bottlenecks, and high-defect areas.
Overview
Value Stream Mapping helps teams:
Identify and remove unnecessary steps
Uncover waiting periods between steps
Highlight steps with high defect rates
The outcome guides the design of an improved value stream, prioritizing changes to reduce waste in the current flow.
Prerequisites
An established process for value delivery (for a “to be” value stream)
Participation from all stakeholders in the value stream
Understanding of key terms:
Wait time/non-value time
Process time/value add time
Percent Complete/Accurate (%C/A)
Recommended Practices
Start mapping from delivery and move backward to ensure no steps are missed.
Process
1. Identify the Source
Example
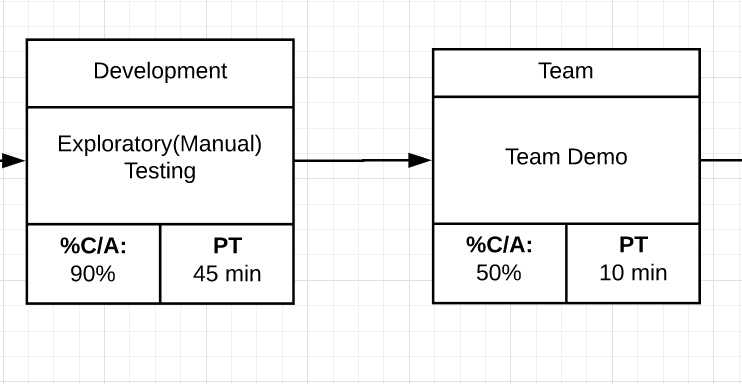
Team Demo
For each source of Requests, determine:
Average process time
Involved stakeholders
Percentage of work rejected by the next step
Process Step Example
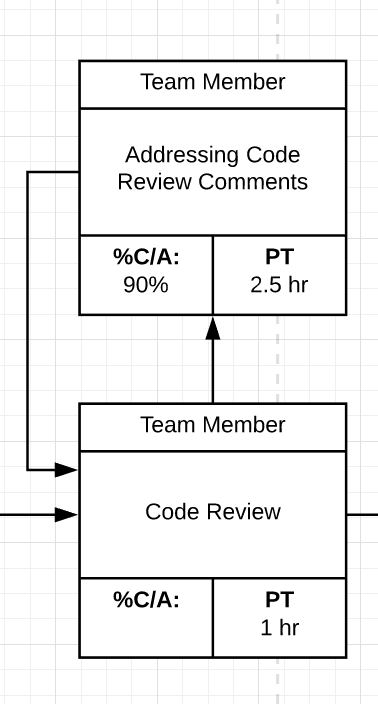
2. Identify Rework Loops
Rework loops are interruptions where steps need correction.
Rework Loop Example
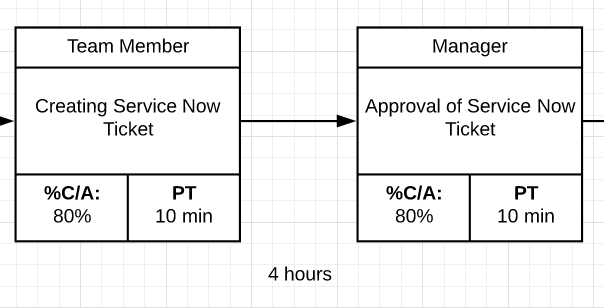
3. Identify Wait Time
Calculate wait time between steps, considering your team’s cadence.
Wait Time Example
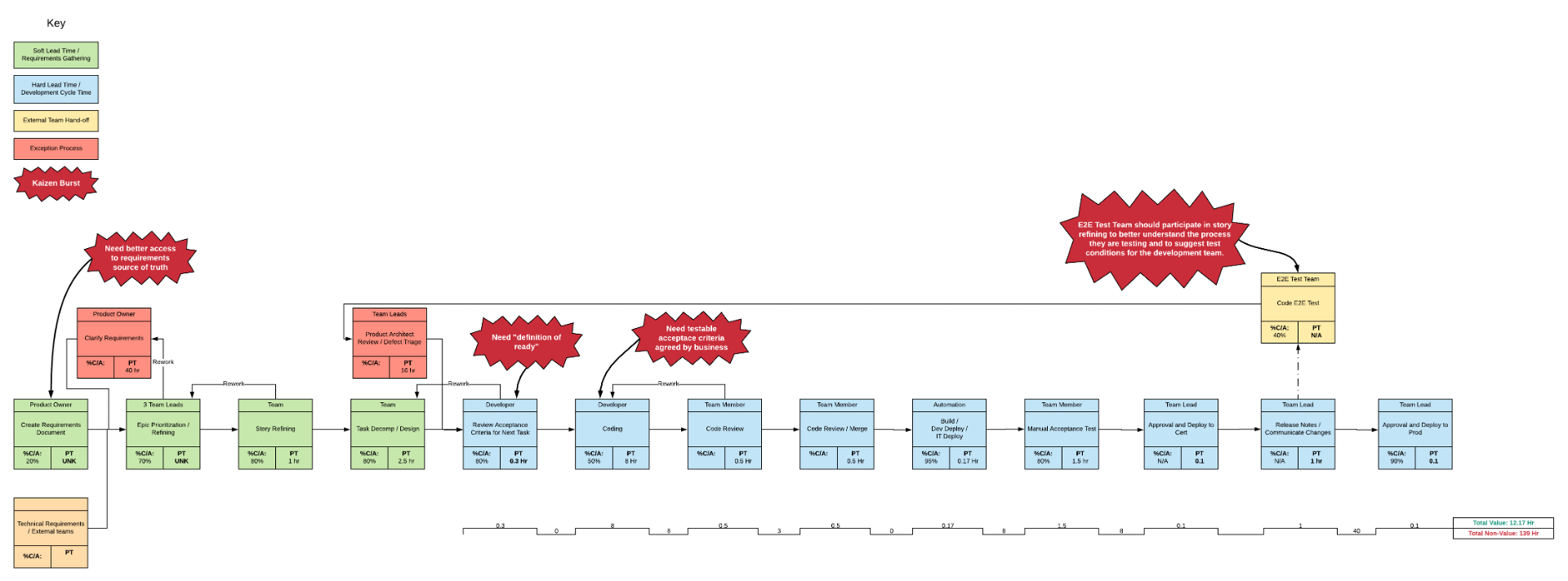
Outcomes
Process time/wait time of your flow
Visual representation of the value stream(s)
Potential constraints (represented as kaizen bursts)
Complete Value Stream Map
Tips
Regularly review and update the value stream map
Consider all potential flows for team processes
Value Proposition
Understanding how to value stream map team processes helps identify delivery constraints and improvement opportunities.
Acceptance Criteria
Value stream all processes associated with delivering value
Create actionable improvement items from the exercise